
为什么使用Redis?
redis是一种典型的no-sql 即非关系数据库,像python的字典一样存储key-value键值,对工作在memory中所以很适合用来充当整个互联网架构中各级之间的cache,比如lvs的4层转发层 nginx的7层代理层,尤其是lnmp架构应用层如php-fpm或者是Tomcat到mysql之间做一个cache 以减轻db的压力因为有相当一部分的数据,只是简单的key-value对应关系,而且在实际的业务中常常在短时间内迅速变动,如果用关系数据库mysql之类存储会大大增加对db的访问,导致db的负担很重 因为所有的require中的大部分最后都要汇聚到DB, 所以如果想要业务稳定那么解决db的压力就是关键,所以现在大部分的解决方案就是在db层之上的各级使用多级的no-sql 像memcache redis等来为db提供缓冲 。
为什么使用Redis-cluster?
为了在大流量访问下提供稳定的业务, 集群化是存储的必然形态,未来的发展趋势肯定是云计算和大数据的紧密结合只有分布式架构能满足要求
文章源自小柒网-https://www.yangxingzhen.cn/1169.html
如果没有集群化 何来的分布式?
虽然Redis这种no-sql一般都是作为cache来服务 但是如果完全没有数据可持久化的方法,那么显得有些单薄就像memcache 由于这种no-sql是工作在memory的,那么由于memory的实体是RAM,所以如果重启或者宕机 memory中的数据就全没了,数据的一致性的不到保障,但是 redis不同,redis有相对的数据持久化的方案,由两种方式构成 aof & rdb。
文章源自小柒网-https://www.yangxingzhen.cn/1169.html
aof就像关系数据库中的binlog一样 把每一次写操作以追加的形式记录在其中以文件的形式刷到磁盘里 并且可以使用不同的fsync策略,无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求)一旦出现故障,最多丢失1秒的数据.但是缺点也随之而来那就是aof文件的大小会随着时间线性增长一段时间之后就会变得很大,如果要在一端以AOF的形式来恢复数据,那么由于AOF文件的巨大体积可能会让进程如同假死一样十分的慢。
文章源自小柒网-https://www.yangxingzhen.cn/1169.html
rdb则是一种快照机制
文章源自小柒网-https://www.yangxingzhen.cn/1169.html
redis工作在内存中rdb就是每隔一段时间对内存中的数据做一次快照保存在rdb文件中,而且redis的主从同步可以实现异步也是由于rdb的机制,他在做快照时会fork出一个子进程由子进程来做快照,父进程完全处理请求毫不影响很适合数据的备份,但是问题是如果数据量很大的话rdb它要保存一个完整的数据集是一个大的工作,如果时间间隔设置的太短那么严重影响redis的性能,但是按照常规设置的话如5分钟一次,那么如果宕机或者重启就会基于上次做rdb的时间从而丢失分钟级的数据。
文章源自小柒网-https://www.yangxingzhen.cn/1169.html
point:在redis4.0的新特性中,采用了aof-rdb的混合方案来保障数据的持久性,但是官方的说法是还不成熟,是一个长期的工作所以有待观察吧
文章源自小柒网-https://www.yangxingzhen.cn/1169.html
Redis集群实现方案:
关于redis的集群化方案 目前有三种
文章源自小柒网-https://www.yangxingzhen.cn/1169.html
1)Twitter开发的twemproxy
文章源自小柒网-https://www.yangxingzhen.cn/1169.html
2)豌豆荚开发的codis
文章源自小柒网-https://www.yangxingzhen.cn/1169.html
3)redis官方的redis-cluster
文章源自小柒网-https://www.yangxingzhen.cn/1169.html
简介:twemproxy架构简单,就是用proxy对后端redis server进行代理,但是由于代理层的消耗性能很低,而且通常涉及多个key的操作都是不支持的,而且本身不支持动态扩容和透明的数据迁移,而且也失去维护Twitter内部已经不使用了。
redis-cluster是三个里性能最强大的,因为他使用去中心化的思想,使用hash slot方式 1634hash slot覆盖到所有节点上,对于存储的每个key值使用CRC16(KEY)&16348=slot,得到他对应的hash slot 并在访问key时就去找他的hash slot在哪一个节点上,然后由当前访问节点从实际被分配了这个hash slot的节点去取数据,节点之间使用轻量协议通信,减少带宽占用、性能很高、自动实现负载均衡与高可用,自动实现failover、并且支持动态扩展,官方已经玩到可以1000个节点,实现的复杂度低 总之个人比较喜欢这个架构因为他的去中心化思想免去了proxy的消耗是全新的思路,
但是它也有一些不足例如官方没有提供图形化管理工具,运维体验差、全手工数据迁移、并且自己对自己本身的redis命令支持也不完全等,但是这些问题我觉得不能掩盖他关键的新思想所带来的的优势,随着官方的推进这些问题应该都能在一定时间内得到解决,那么这时候去中心化思想带来的高性能就会表现出他巨大的优势。
codis使用的也是proxy思路,但是做的比较好,是这两种之间的一个中间级,而且支持redis命令是最多的,有图形化GUI管理和监控工具,运维友好。
Redis集群基本介绍
Redis 集群是一个可以在多个 Redis 节点之间进行数据共享的设施installation。
Redis 集群不支持那些需要同时处理多个键的 Redis 命令, 因为执行这些命令需要在多个 Redis 节点之间移动数据, 并且在高负载的情况下, 这些命令将降低Redis集群的性能, 并导致不可预测的行为。
Redis 集群通过分区partition来提供一定程度的可用性availability: 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
Redis集群提供了以下两个好处:
将数据自动切分split到多个节点的能力。
当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力。
集群原理
所有的Redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
节点的fail是通过集群中超过半数的节点检测失效时才生效。
客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
Redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
Redis-cluster投票:容错
投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超时(cluster-node-timeout),认为当前master节点挂掉.
什么时候整个集群不可用(cluster_state:fail)?
如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完整时进入fail状态.
Redis-3.0.0.rc1加入cluster-require-full-coverage参数,默认关闭,打开集群兼容部分失败.
如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态.
Redis-cluster集群搭建
环境准备:CentOS 7.4
1、安装wget和gcc
[root@localhost ~]# yum -y install wget gcc gcc-c++
2、下载Redis安装包
[root@localhost ~]# wget -c http://mirrors.yangxingzhen.com/redis/redis-3.0.7.tar.gz
3、解压和创建存放目录
[root@localhost ~]# tar zxf redis-3.0.7.tar.gz
[root@localhost ~]# cd redis-3.0.7
[root@localhost redis-3.0.7]# make
[root@localhost redis-3.0.7]# mkdir -p /usr/local/redis-cluster
4、拷贝redis目录
[root@localhost redis-3.0.7]# cd ~
[root@localhost ~]# cp -a redis-3.0.7 /usr/local/redis-cluster/redis_7000
[root@localhost ~]# cp -a redis-3.0.7 /usr/local/redis-cluster/redis_7001
[root@localhost ~]# cp -a redis-3.0.7 /usr/local/redis-cluster/redis_7002
[root@localhost ~]# cp -a redis-3.0.7 /usr/local/redis-cluster/redis_7003
[root@localhost ~]# cp -a redis-3.0.7 /usr/local/redis-cluster/redis_7004
[root@localhost ~]# cp -a redis-3.0.7 /usr/local/redis-cluster/redis_7005
5、将六个节点的redis.conf配置文件进行修改(这里采用的是脚本修改)
[root@localhost ~]# vim auto_modify_port.sh
#!/bin/bash
#2018-4-27 14:49:49
for i in `seq 7000 7005`
do
cd /usr/local/redis-cluster/redis_$i
sed -i "/port/s/6379/$i/" /usr/local/redis-cluster/redis_$i/redis.conf
sed -i '/appendonly/s/no/yes/' /usr/local/redis-cluster/redis_$i/redis.conf
sed -i '/daemonize/s/no/yes/' /usr/local/redis-cluster/redis_$i/redis.conf
cat >>/usr/local/redis-cluster/redis_$i/redis.conf <<-EOF
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
EOF
done
PS:端口号如果是同一台主机的话,必须不同。不同主机可以相同。
PS:我这里是使用一台主机,所以我将六个节点的端口号修改为7000-7005
6、编写集群启动脚本
[root@localhost ~]# vim auto_redis_start.sh
#!/bin/bash
#2018-4-27 15:00:40
for i in `seq 7000 7005`
do
cd /usr/local/redis-cluster/redis_$i/src
./redis-server ../redis.conf
done
7、编写集群停止脚本
[root@localhost ~]# vim auto_redis_shutdown.sh
#!/bin/bash
#2018-4-27 15:01:54
for i in `seq 7000 7005`
do
cd /usr/local/redis-cluster/redis_$i/src
./redis-cli -p $i shutdown
done
8、安装ruby的环境,这里推荐使用yum安装
[root@localhost ~]# yum -y install ruby rubygems
9、拷贝源码包的redis-trib.rb文件
[root@localhost ~]# cp redis-3.0.7/src/redis-trib.rb ~
启动redis集群
[root@localhost ~]# sh auto_redis_start.sh
[root@localhost ~]# netstat -lntup
10、执行redis的创建集群命令创建集群
[root@localhost ~]# ./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005

出现报错,由于ruby版本较低导致
11、升级ruby版本
[root@localhost ~]# curl -L get.rvm.io | bash -s stable
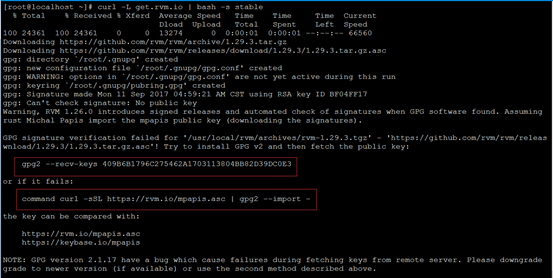
由于没有密钥导致,按照提示输入
[root@localhost ~]# gpg2 --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3
[root@localhost ~]# curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
再执行一次即可
[root@localhost ~]# curl -L get.rvm.io | bash -s stable
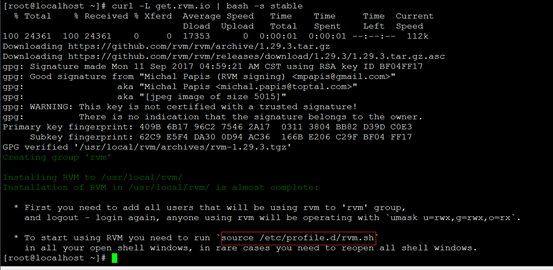
执行source /etc/profile.d/rvm.sh即可
12、安装ruby
查看Ruby可用版本
[root@localhost ~]# rvm list known
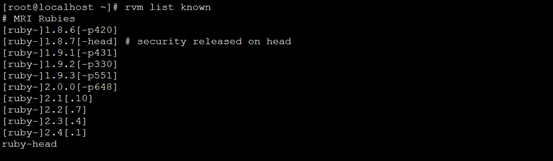
这里查询到2.4.1是最新的,那就安装最新的吧
[root@localhost ~]# rvm install 2.4.1
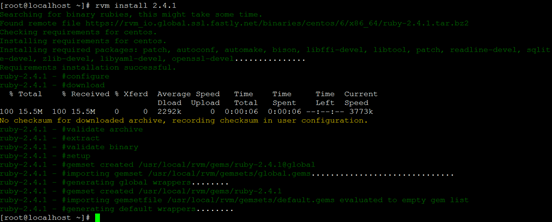
至此,我们升级了Ruby的版本
13、安装gem redis接口
[root@localhost ~]# gem install redis
14、继续执行redis的创建集群命令创建集群
[root@localhost ~]# ./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
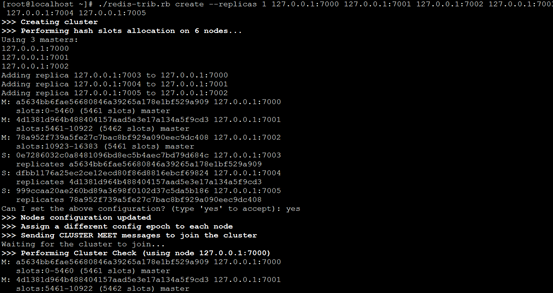
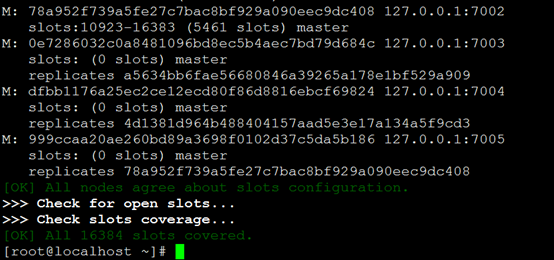
可以看到16384个slot都已经创建完成,并且建立了3个master和对应的replica
15、验证集群状态
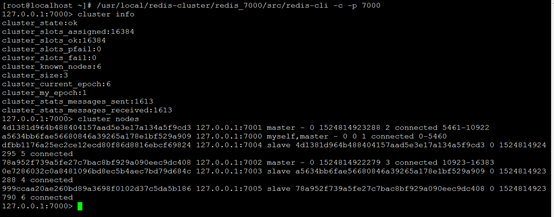
[root@localhost ~]# /usr/local/redis-cluster/redis_7000/src/redis-cli -c -p 7000
127.0.0.1:7000> cluster info
127.0.0.1:7000> cluster nodes
16、测试 Redis 集群比较简单的办法就是使用 redis-rb-cluster 或者 redis-cli , 接下来我们将使用 redis-cli 为例来进行演示:
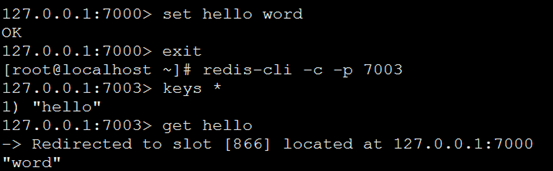
17、添加主节点
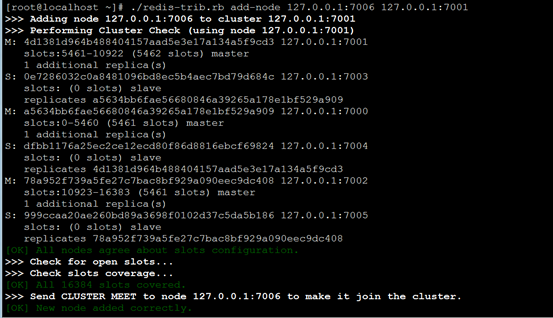
集群创建成功后可以向集群中添加节点,下面是添加一个master主节点。
首先,准备一个干净的redis节点。按上面集群版修改redis配置文件。开启该redis节点。
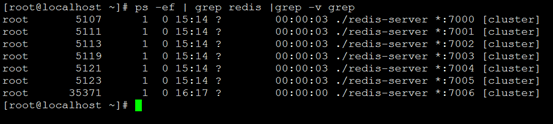
18、查看Redis进程
[root@localhost ~]# ps -ef | grep redis |grep -v grep
[root@localhost ~]# ./redis-trib.rb add-node 127.0.0.1:7006 127.0.0.1:7001
19、查看集群状态,是否把7006添加进来
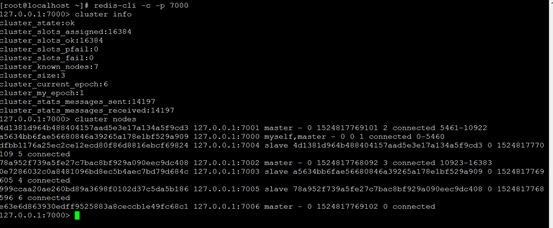
20、添加从节点
集群创建成功后可以向集群中添加节点,下面是添加一个slave从节点。
添加7007从结点,将7007作为7006的从结点。
首先,准备一个干净的redis节点。按上面集群版修改redis配置文件。开启该redis节点。
21、查看Redis进程
命令格式为:
./redis-trib.rb add-node --slave --master-id 主节点id 添加节点的ip和端口 集群中已存在节点ip和端口
若文章图片、下载链接等信息出错,请在评论区留言反馈,博主将第一时间更新!如本文“对您有用”,欢迎随意打赏,谢谢!


评论