
一、Flink 简介
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
1、无界流和有界流
文章源自小柒网-https://www.yangxingzhen.cn/7561.html
任何类型的数据都是作为事件流产生的。信用卡交易,传感器测量,机器日志或网站或移动应用程序上的用户交互,所有这些数据都作为流生成。
文章源自小柒网-https://www.yangxingzhen.cn/7561.html
数据可以作为无界或有界流处理。
文章源自小柒网-https://www.yangxingzhen.cn/7561.html
- 无界流有一个开始但没有定义的结束。它们不会在生成时终止并提供数据。必须持续处理无界流,即必须在摄取事件后立即处理事件。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断结果完整性。
- 有界流具有定义的开始和结束。可以在执行任何计算之前通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理。
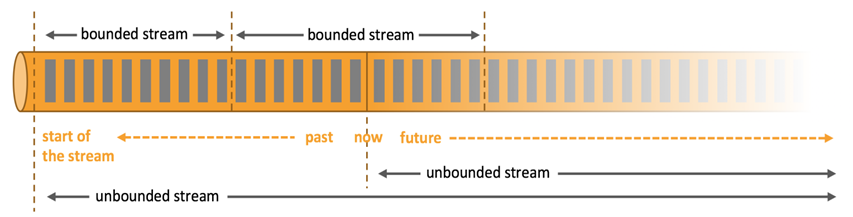 文章源自小柒网-https://www.yangxingzhen.cn/7561.html
文章源自小柒网-https://www.yangxingzhen.cn/7561.html
Apache Flink擅长处理无界和有界数据集。精确控制时间和状态使Flink的运行时能够在无界流上运行任何类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而产生出色的性能。
文章源自小柒网-https://www.yangxingzhen.cn/7561.html
2、随处部署应用程序
文章源自小柒网-https://www.yangxingzhen.cn/7561.html
Apache Flink是一个分布式系统,需要计算资源才能执行应用程序。Flink与所有常见的集群资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以设置为作为独立集群运行。
文章源自小柒网-https://www.yangxingzhen.cn/7561.html
Flink旨在很好地适用于之前列出的每个资源管理器。这是通过特定于资源管理器的部署模式实现的,这些模式允许Flink以其惯用的方式与每个资源管理器进行交互。
文章源自小柒网-https://www.yangxingzhen.cn/7561.html
部署Flink应用程序时,Flink会根据应用程序配置的并行性自动识别所需资源,并从资源管理器请求它们。如果发生故障,Flink会通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都通过REST调用进行。这简化了Flink在许多环境中的集成。
文章源自小柒网-https://www.yangxingzhen.cn/7561.html
3、以任何比例运行应用程序
文章源自小柒网-https://www.yangxingzhen.cn/7561.html
Flink旨在以任何规模运行有状态流应用程序。应用程序可以并行化为数千个在集群中分布和同时执行的任务。因此,应用程序可以利用几乎无限量的CPU,主内存,磁盘和网络IO。而且,Flink可以轻松维护非常大的应用程序状态。其异步和增量检查点算法确保对处理延迟的影响最小,同时保证一次性状态一致性。
用户报告了在其生产环境中运行的Flink应用程序的可扩展性数字令人印象深刻,例如
- 应用程序每天处理数万亿个事件
- 应用程序维护多个TB的状态
- 应用程序在数千个内核的运行
4、利用内存中的性能
有状态Flink应用程序针对本地状态访问进行了优化。任务状态始终保留在内存中,或者,如果状态大小超过可用内存,则保存在访问高效的磁盘上数据结构中。因此,任务通过访问本地(通常是内存中)状态来执行所有计算,从而产生非常低的处理延迟。Flink通过定期和异步检查本地状态到持久存储来保证在出现故障时的一次状态一致性。
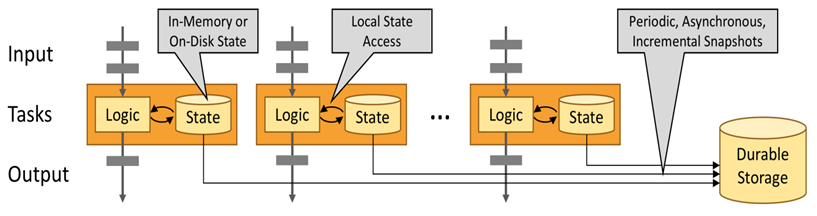
5、Flink的架构
Flink可以支持本地的快速迭代,以及一些环形的迭代任务。并且Flink可以定制化内存管理。在这点,如果要对比Flink和Spark的话,Flink 并没有将内存完全交给应用层。这也是为什么Spark相对于Flink,更容易出现OOM的原因(out of memory)。就框架本身与应用场景来说,Flink更相似与Storm。如果之前了解过Storm或者Flume的读者,可能会更容易理解Flink的架构和很多概念。下面让我们先来看下Flink的架构图。
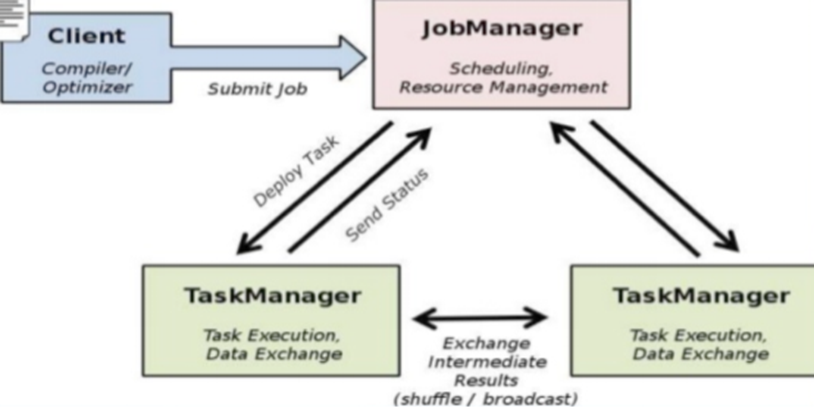
我们可以了解到Flink几个最基础的概念,Client、JobManager和TaskManager。Client用来提交任务给JobManager,JobManager分发任务给TaskManager去执行,然后TaskManager会心跳的汇报任务状态。看到这里,有的人应该已经有种回到Hadoop一代的错觉。确实,从架构图去看,JobManager 很像当年的 JobTracker,TaskManager也很像当年的TaskTracker。然而有一个最重要的区别就是TaskManager之间是是流(Stream)。其次,Hadoop一代中,只有Map和Reduce之间的Shuffle,而对Flink而言,可能是很多级,并且在TaskManager内部和TaskManager之间都会有数据传递,而不像Hadoop,是固定的Map到Reduce。
三、Flink技术特点
1、流处理特性
- 支持高吞吐、低延迟、高性能的流处理
- 支持带有事件时间的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
- 支持具有Backpressure功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 一个运行时同时支持Batch on Streaming处理和Streaming处理
- Flink在JVM内部实现了自己的内存管理
- 支持迭代计算
- 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
2、API支持
- 对Streaming数据类应用,提供DataStream API
- 对批处理类应用,提供DataSet API(支持Java/Scala)
3、Libraries支持
- 支持机器学习(FlinkML)
- 支持图分析(Gelly)
- 支持关系数据处理(Table)
- 支持复杂事件处理(CEP)
4、整合支持
- 支持Flink on YARN
- 支持HDFS
- 支持来自Kafka的输入数据
- 支持Apache HBase
- 支持Hadoop程序
- 支持Tachyon
- 支持ElasticSearch
- 支持RabbitMQ
- 支持Apache Storm
- 支持S3
- 支持XtreemFS
5、Flink生态圈
Flink首先支持了Scala和Java的API,Python也正在测试中。Flink通过Gelly支持图像处理操作,还有机器学习的 FlinkML。Table是一种接口化的SQL支持,也就是API支持,而不是文本化的SQL解析和执行。对于完整的Stack我们可以参考下图。
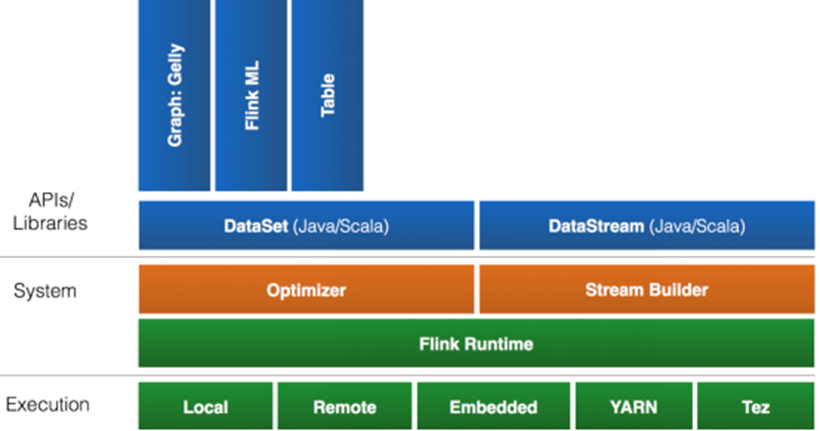
Flink为了更广泛的支持大数据的生态圈,其下也实现了很多Connector的子项目。最熟悉的,当然就是与Hadoop HDFS集成。其次,Flink也宣布支持了 Tachyon、S3以及MapRFS。不过对于Tachyon以及S3的支持,都是通过 Hadoop HDFS这层包装实现的,也就是说要使用Tachyon和S3,就必须有Hadoop,而且要更改Hadoop的配置(core-site.xml)。如果浏览Flink的代码目录,我们就会看到更多Connector项目,例如Flume和Kafka。
四、Flink的编程模型
Flink提供不同级别的抽象来开发流/批处理应用程序。
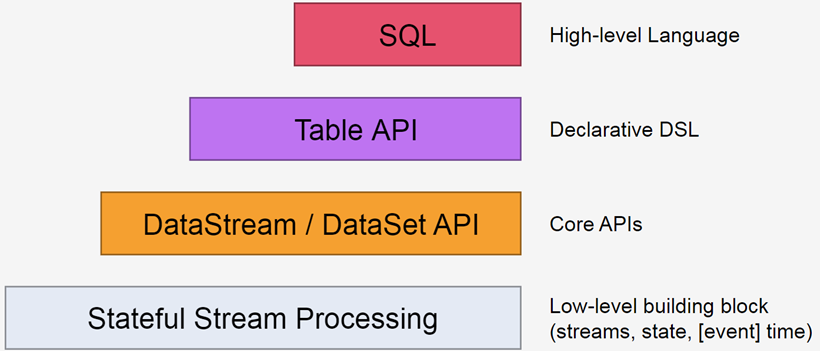
五、Hadoop分布式集群部署
由于Flink HA模式(基于Standalone)需要使用HDFS,需要部署Hadoop集群,可参考我前面写的文章(Linux搭建Hadoop-2.7.2分布式集群)
六、Flink的下载
安装包下载地址:http://flink.apache.org/downloads.html,选择对应Hadoop的Flink版本下载
Flink有三种部署模式,分别是Local、Standalone Cluster和Yarn Cluster。
1、Local模式
对于Local模式来说,JobManager和TaskManager会共用一个JVM来完成Workload。如果要验证一个简单的应用,Local模式是最方便的。实际应用中大多使用Standalone或者Yarn Cluster,而local模式只是将安装包解压启动(./bin/start-local.sh)即可
1)下载Flink
[root@localhost ~]# wget https://archive.apache.org/dist/flink/flink-1.7.2/flink-1.7.2-bin-hadoop27-scala_2.12.tgz
2)解压
[root@localhost ~]# tar xf flink-1.7.2-bin-hadoop27-scala_2.12.tgz -C /usr/local
3)配置环境变量
[root@localhost ~]# vim /etc/profile
export Flink_Home=/usr/local/flink-1.7.2
export PATH=$PATH:$Flink_Home/bin
[root@localhost ~]# source /etc/profile
4)启动Flink服务
[root@localhost ~]# ./start-cluster.sh
2、Standalone模式
快速入门教程地址:https://ci.apache.org/projects/flink/flink-docs-release-1.6/quickstart/setup_quickstart.html
1)软件要求
- Java 1.8.x或更高版本,这里采用1.8_181
- ssh(必须运行sshd才能使用管理远程组件的Flink脚本)
2)集群部署规划
|
节点名称 |
IP地址 |
master |
worker |
zookeeper |
|
master |
172.168.1.157 |
master |
zookeeper |
|
|
node1 |
172.168.1.158 |
master |
worker |
zookeeper |
|
node2 |
172.168.1.159 |
worker |
zookeeper |
3)下载Flink
[root@master ~]# wget https://archive.apache.org/dist/flink/flink-1.7.2/flink-1.7.2-bin-hadoop27-scala_2.12.tgz
4)解压
[root@master ~]# tar xf flink-1.7.2-bin-hadoop27-scala_2.12.tgz -C /usr/local
5)修改配置文件
# 修改masters、slaves、flink-conf.yaml
[root@master ~]# cd /usr/local/flink-1.7.2/conf
[root@master conf]# echo "master" > masters
[root@master conf]# cat masters
master
[root@master conf]# echo -e "master\nnode1\nnode2" > slaves
[root@master conf]# cat slaves
master
node1
node2
[root@master conf]# sed -i '/jobmanager.rpc.address/s/localhost/master/' flink-conf.yaml
# 根据实际情况更改
[root@master conf]# sed -i '/taskmanager.numberOfTaskSlots/s/1/4/' flink-conf.yaml
可选配置:
- 每个JobManager(jobmanager.heap.mb)的可用内存量
- 每个TaskManager(taskmanager.heap.mb)的可用内存量
- 每台机器的可用CPU数量(taskmanager.numberOfTaskSlots)
- 集群中的CPU总数(parallelism.default)和
- 临时目录(taskmanager.tmp.dirs)
6)配置hosts
[root@master conf]# vim /etc/hosts
# 添加以下内容
172.168.1.157 master
172.168.1.158 node1
172.168.1.159 node2
7)配置免密钥
[root@master ~]# ssh-keygen
# 输入三次确定
[root@master ~]# ssh-copy-id root@master
[root@master ~]# ssh-copy-id root@node1
[root@master ~]# ssh-copy-id root@node2
8)配置环境变量
[root@master ~]# vim /etc/profile
export Flink_Home=/usr/local/flink-1.7.2
export PATH=$PATH:$Flink_Home/bin
9)拷贝profile、hosts文件、Flink安装目录到各节点
[root@master ~]# scp /etc/profile root@node1:/etc/
[root@master ~]# scp /etc/profile root@node2:/etc/
[root@master ~]# scp /etc/hosts root@node1:/etc/
[root@master ~]# scp /etc/hosts root@node2:/etc/
[root@master ~]# scp -r /usr/local/flink-1.7.2/ root@node1:/usr/local/
[root@master ~]# scp -r /usr/local/flink-1.7.2/ root@node2:/usr/local/
10)执行source /etc/profile使其环境变量生效
[root@master ~]# source /etc/profile
[root@node1 ~]# source /etc/profile
[root@node1 ~]# source /etc/profile
11)启动Flink服务
[root@master conf]# start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host master.
Starting taskexecutor daemon on host master.
Starting taskexecutor daemon on host node1.
Starting taskexecutor daemon on host node2.
10)jps查看进程
[root@master ~]# jps
2135 Jps
2041 StandaloneSessionClusterEntrypoin
2057 TaskManagerRunner
[root@node1 ~]# jps
2964 Jps
2891 TaskManagerRunner
[root@node2 ~]# jps
15408 TaskManagerRunner
15480 Jps
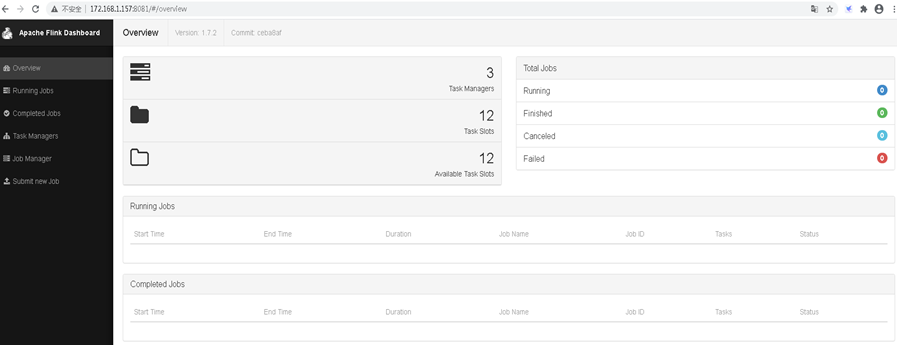
11)WebUI查看
# 浏览器访问http://172.168.1.157:8081,如下图
3、Flink的HA模式(基于Standalone模式)
首先,我们需要知道Flink有两种部署的模式,分别是Standalone以及Yarn Cluster模式。对于Standalone来说,Flink必须依赖于Zookeeper来实现 JobManager的HA(Zookeeper已经成为了大部分开源框架HA必不可少的模块)。在Zookeeper的帮助下,一个Standalone的Flink集群会同时有多个活着的JobManager,其中只有一个处于工作状态,其他处于Standby状态。当工作中的JobManager失去连接后(如宕机或Crash),Zookeeper会从Standby中选举新的JobManager来接管Flink集群。
对于Yarn Cluaster模式来说,Flink就要依靠Yarn本身来对JobManager做HA了。其实这里完全是Yarn的机制。对于Yarn Cluster模式来说,JobManager和TaskManager都是被Yarn启动在Yarn的Container中。此时的JobManager,其实应该称之为Flink Application Master。也就说它的故障恢复,就完全依靠着Yarn中的ResourceManager(和MapReduce的AppMaster一样)。由于完全依赖了Yarn,因此不同版本的Yarn可能会有细微的差异。这里不再做深究。
1)修改配置文件
修改flink-conf.yaml,HA模式下,jobmanager不需要指定,在master文件中配置,由zookeeper选出leader与standby。
[root@master ~]# cd /usr/local/flink-1.7.2/conf
[root@master conf]# vim flink-conf.yaml
# 配置内容如下
# jobManager 的IP地址
#jobmanager.rpc.address: master
# JobManager 的端口号
jobmanager.rpc.port: 6123
# JobManager JVM堆大小
jobmanager.heap.size: 1024m
# Taskmanager JVM堆大小
taskmanager.heap.size: 1024m
# 每个 TaskManager 提供的任务 slots 数量
taskmanager.numberOfTaskSlots: 4
# 程序默认并行计算的个数,最大并行计算个数为所有的taskmanager上面的slots总和
parallelism.default: 1
# 指定高可用模式(必须)
high-availability: zookeeper
# 存储目录 (required): JobManager的元数据保存在文件系统存储目录 storageDir 中,只有一个指向此状态的指针存储在ZooKeeper中(必须)
high-availability.storageDir: hdfs://master:9000/flink/ha/
# ZooKeeper仲裁是ZooKeeper服务器的复制组,它提供分布式协调服务(必须)
high-availability.zookeeper.quorum: master:2181,node1:2181,node2:2181
# ZooKeeper节点根目录,在该节点下放置所有集群节点(推荐)
high-availability.zookeeper.path.root: /flink
# ZooKeeper 集群id (推荐的): ZooKeeper节点集群id,其中放置了集群所需的所有协调数据。(推荐)
high-availability.cluster-id: /flinkCluster
# 用于存储和检查点状态
state.backend: filesystem
# 存储检查点的数据文件和元数据的默认目录
state.checkpoints.dir: hdfs://master:9000/flink/checkpoints
# savepoints 的默认目标目录(可选)
state.savepoints.dir: hdfs://master:9000/flink/checkpoints
# Web UI端口号
rest.port: 8081
[root@master conf]# vim zoo.cfg
server.1=master:2888:3888
server.2=node1:2888:3888
server.3=node2:2888:3888
[root@master conf]# vim masters
master:8081
node1:8081
2)同步配置文件到各个节点
[root@master conf]# scp -r /usr/local/flink-1.7.2/ root@node1:/usr/local/
[root@master conf]# scp -r /usr/local/flink-1.7.2/ root@node2:/usr/local/
3)启动HA
先启动zookeeper集群各节点(测试环境中也可以用Flink自带的start-zookeeper-quorum.sh),启动dfs ,再启动Flink
[root@master conf]# start-zookeeper-quorum.sh
Starting zookeeper daemon on host master.
Starting zookeeper daemon on host node1.
Starting zookeeper daemon on host node2.
# jps查看进程
[root@master conf]# jps
3089 FlinkZooKeeperQuorumPeer
3860 Jps
[root@node1 ~]# jps
4995 Jps
3707 FlinkZooKeeperQuorumPeer
[root@node2 ~]# jps
16482 Jps
15980 FlinkZooKeeperQuorumPeer
4)启动HDFS
[root@master ~]# /usr/local/hadoop-2.7.2/sbin/start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-namenode-master.out
node1: starting datanode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-datanode-node1.out
master: starting datanode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-datanode-master.out
node2: starting datanode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-datanode-node2.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-master.out
5)启动Flink
[root@master conf]# start-cluster.sh
Starting HA cluster with 2 masters.
Starting standalonesession daemon on host master.
Starting standalonesession daemon on host node1.
Starting taskexecutor daemon on host master.
Starting taskexecutor daemon on host node1.
Starting taskexecutor daemon on host node2.
6)使用jps查看进程信息
[root@master conf]# jps |grep -vi jps
31473 TaskManagerRunner
3267 NameNode
3892 NodeManager
9014 FlinkZooKeeperQuorumPeer
3786 ResourceManager
3403 DataNode
30987 StandaloneSessionClusterEntrypoint
3581 SecondaryNameNode
[root@node1 ~]# jps |grep -vi jps
20211 TaskManagerRunner
1799 DataNode
1927 NodeManager
3613 FlinkZooKeeperQuorumPeer
19743 StandaloneSessionClusterEntrypoint
[root@node2 ~]# jps |grep -vi jps
2837 DataNode
17465 TaskManagerRunner
3050 NodeManager
5198 FlinkZooKeeperQuorumPeer
4、测试HA
1)配置hosts文件(Windows系统)
# hosts文件路径C:\Windows\System32\drivers\etc\hosts
172.168.1.157 master
172.168.1.158 node1
172.168.1.159 node2
2)访问Leader的Flink WebUI
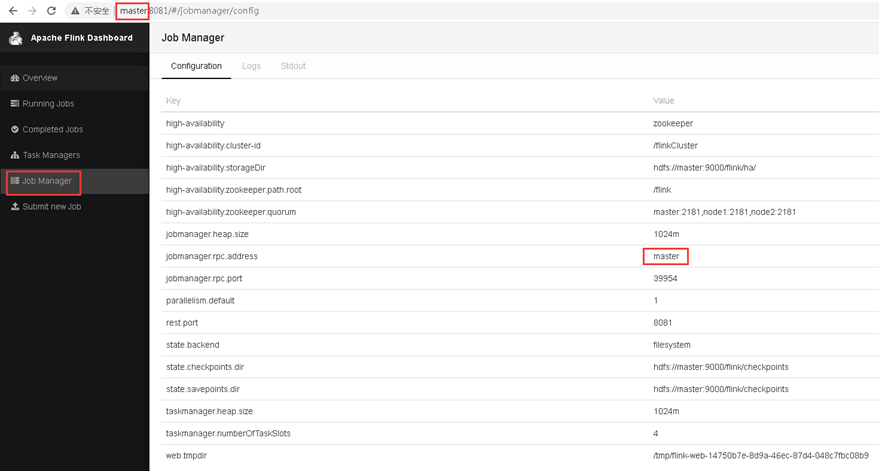
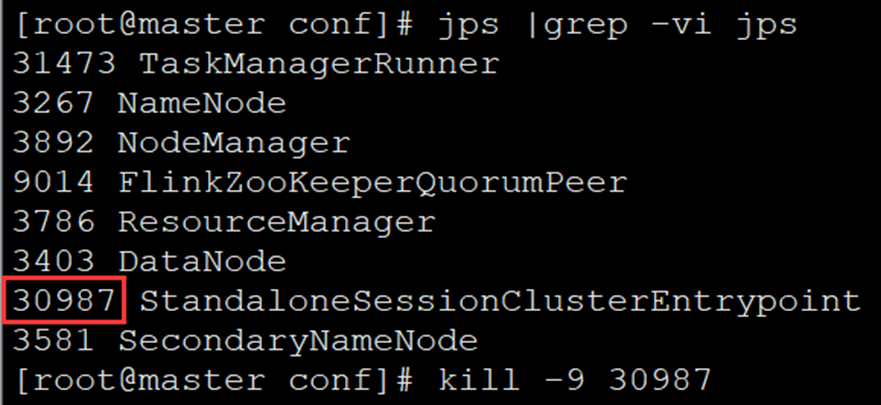
3)Kill掉Leader
[root@master conf]# kill -9 30987
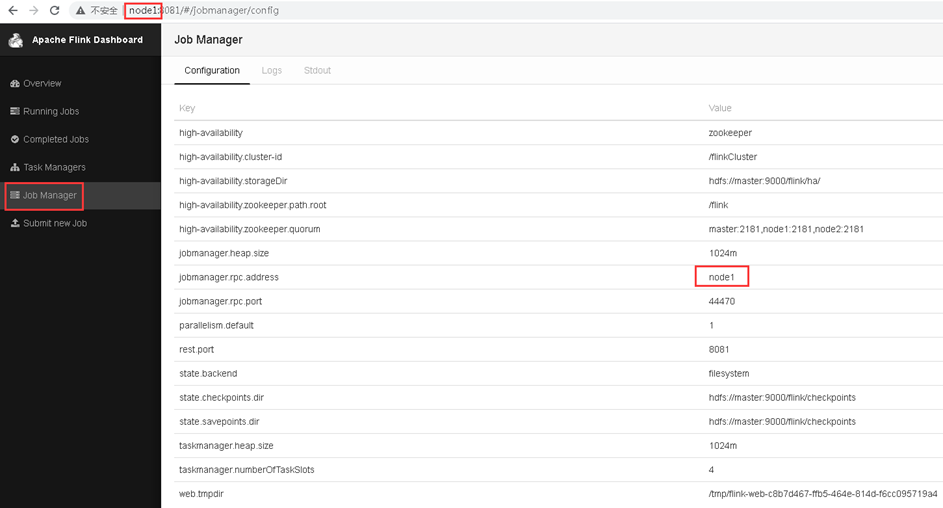
4)再次访问Flink WebUI,发现Leader已经发生切换
5)重启master的JobManager
[root@master conf]# jobmanager.sh start cluster
Starting standalonesession daemon on host master.
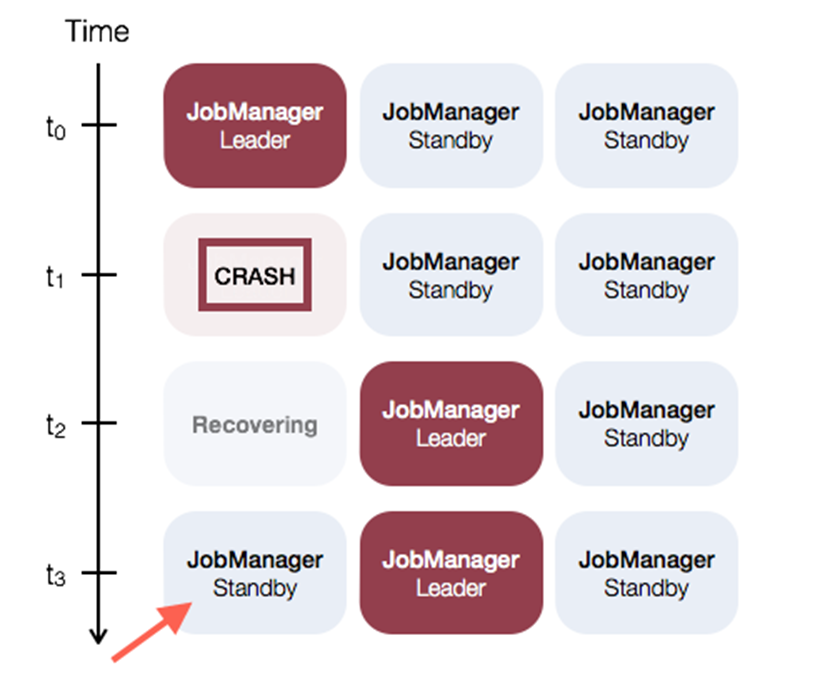
6)再次查看Flink WebUI,发现虽然以前被Kill掉的Leader起来了,但是现在仍是StandBy,现有的Leader不会发生切换,也就是Flink下面的示意图:
至此,Linux搭建Flink-1.7.2 HA集群(基于Standalone模式)完毕。
七、Yarn 模式(略)
若文章图片、下载链接等信息出错,请在评论区留言反馈,博主将第一时间更新!如本文“对您有用”,欢迎随意打赏,谢谢!


评论