
1、Hive入门教程
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。
在Hive中,Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/RJob里使用这些数据。
文章源自小柒网-https://www.yangxingzhen.cn/7714.html
最初,Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下ApacheHive为一个开源项目。它用在好多不同的公司。例如,亚马逊使用它在Amazon Elastic、MapReduce。
文章源自小柒网-https://www.yangxingzhen.cn/7714.html
1)Hive原理图
文章源自小柒网-https://www.yangxingzhen.cn/7714.html
 文章源自小柒网-https://www.yangxingzhen.cn/7714.html
文章源自小柒网-https://www.yangxingzhen.cn/7714.html
2)Hive系统架构
文章源自小柒网-https://www.yangxingzhen.cn/7714.html
Hive系统架构图:
文章源自小柒网-https://www.yangxingzhen.cn/7714.html
-
用户接口:
CLI,即Shell命令行。
文章源自小柒网-https://www.yangxingzhen.cn/7714.html
JDBC/ODBC是Hive的Java,与使用传统数据库JDBC的方式类似。
文章源自小柒网-https://www.yangxingzhen.cn/7714.html
WebGUI是通过浏览器访问Hive。
文章源自小柒网-https://www.yangxingzhen.cn/7714.html
Thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引擎,以构建在 C++,Java, Go,Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript,Node.js, Smalltalk, and OCaml这些编程语言间无缝结合的、高效的服务。
文章源自小柒网-https://www.yangxingzhen.cn/7714.html
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
Hive的数据存储在HDFS中,大部分的查询由MapReduce完成(包含*的查询,比如select *from table不会生成MapRedcue任务)。
Hive将元数据存储在数据库中(metastore),目前只支持mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
-
Metastore组件
Hive的Metastore组件是Hive元数据集中存放地。Metastore组件包括两个部分:Metastore服务和后台数据的存储。后台数据存储的介质就是关系数据库,例如Hive默认的嵌入式磁盘数据库derby,还有mysql数据库。Metastore服务是建立在后台数据存储介质之上,并且可以和Hive服务进行交互的服务组件,默认情况下,Metastore服务和Hive服务是安装在一起的,运行在同一个进程当中。我也可以把Metastore服务从Hive服务里剥离出来,Metastore独立安装在一个集群里,Hive远程调用Metastore服务,这样我们可以把元数据这一层放到防火墙之后,客户端访问Hive服务,就可以连接到元数据这一层,从而提供了更好的管理性和安全保障。使用远程的Metastore服务,可以让Metastore服务和hive服务运行在不同的进程里,这样也保证了Hive的稳定性,提升了Hive服务的效率。
Hive的执行流程如下图所示:
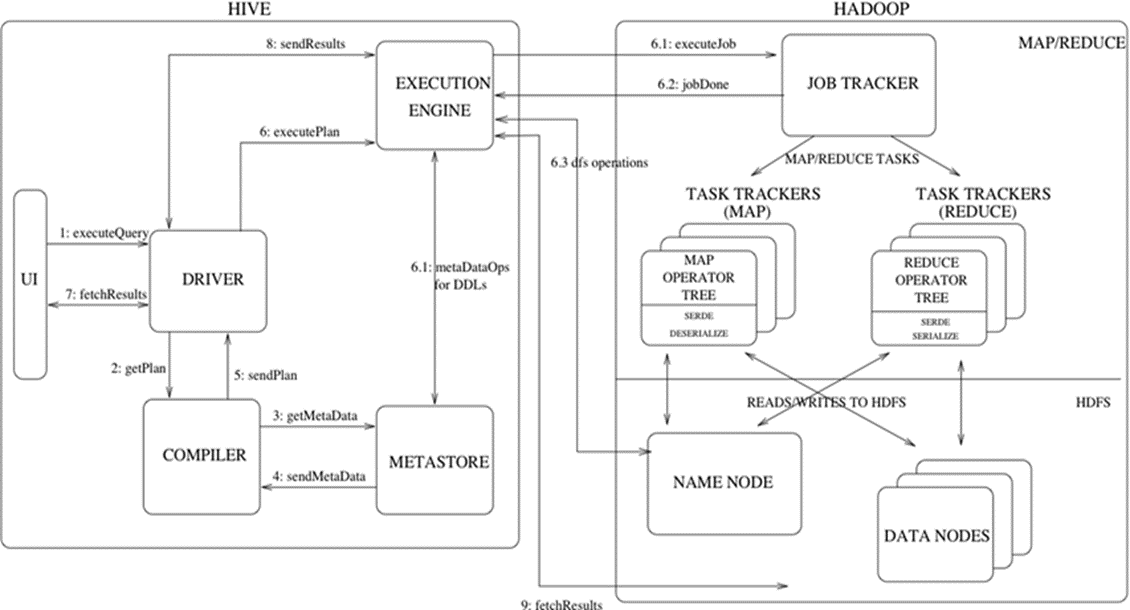
Hive是建立Hadoop环境安装之上的,所以需要Hadoop的集群环境搭建,Hive即需要依赖于HDFS又需要依赖YARN。安装好Hadoop后需要进行启动HDFS和YARN。
环境安装参考资料:Linux搭建Hadoop-2.7.2分布式集群
环境安装参考资料:
1、Hive下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.7/apache-hive-2.3.7-bin.tar.gz
2、Hadoop和Hbase版本关系表:
|
Hive版本 |
Hadoop版本 |
| Hive-2.3.0 |
2.x.y |
| Hive-2.2.0 |
2.x.y |
| Hive-2.1.1 |
2.x.y |
| Hive-2.1.0 |
2.x.y |
| Hive-2.0.0 |
2.x.y |
| Hive-1.2.2 |
1.x.y、2.x.y |
| Hive-1.2.1 |
1.x.y、2.x.y |
| Hive-1.1.1 |
1.x.y、2.x.y |
| Hive-1.0.1 |
1.x.y、2.x.y |
| Hive-1.0.0 |
1.x.y、2.x.y |
| Hive-0.13.1 |
0.20.x.y、0.23.x.y、1.x.y、2.x.y |
| Hive-0.13.0 |
0.20.x.y、0.23.x.y、1.x.y、2.x.y |
| Hive-0.12.0 |
0.20.x.y、0.23.x.y、1.x.y、2.x.y |
| Hive-0.11.0 |
0.20.x.y、0.23.x.y、1.x.y、2.x.y |
| Hive-0.10.0 |
0.20.x.y、0.23.x.y、1.x.y、2.x.y |
4)安装Hive
1、下载Hive安装包
[root@node1 ~]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.7/apache-hive-2.3.7-bin.tar.gz
2、解压Hive安装包
[root@node1 ~]# tar xf apache-hive-2.3.7-bin.tar.gz
[root@node1 ~]# mv apache-hive-2.3.7-bin /usr/local/hive
[root@node1 ~]# ls -l /usr/local/hive/
total 56
drwxr-xr-x 3 root root 133 Dec 3 10:56 bin
drwxr-xr-x 2 root root 4096 Dec 3 10:56 binary-package-licenses
drwxr-xr-x 2 root root 4096 Dec 3 10:56 conf
drwxr-xr-x 4 root root 34 Dec 3 10:56 examples
drwxr-xr-x 7 root root 68 Dec 3 10:56 hcatalog
drwxr-xr-x 2 root root 44 Dec 3 10:56 jdbc
drwxr-xr-x 4 root root 12288 Dec 3 10:56 lib
-rw-r--r-- 1 root root 20798 Mar 10 2020 LICENSE
-rw-r--r-- 1 root root 230 Apr 8 2020 NOTICE
-rw-r--r-- 1 root root 361 Apr 8 2020 RELEASE_NOTES.txt
drwxr-xr-x 4 root root 35 Dec 3 10:56 scripts
注解:
bin:包含hive的命令shell脚本
binary-package-licenses:包含了LICENSE说明文件
conf:包含hive配置文件
examples:包含了示例
hcatalog:Metastore操作的元数据目录
jdbc:提供了hive-jdbc-2.3.0-standalone.jar包
scripts:提供了sql脚本
3、配置环境变量
[root@node1 ~]# vim /etc/profile
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
4、执行命令source /etc/profile使其生效
[root@node1 ~]# source /etc/profile
5、配置Hive
[root@node1 ~]# cd /usr/local/hive/conf
[root@node1 conf]# cp hive-default.xml.template hive-site.xml
# 新建HDFS目录
[root@node1 conf]# hadoop fs -mkdir -p /data/hive/warehouse
[root@node1 conf]# hadoop fs -mkdir -p /data/hive/tmp
[root@node1 conf]# hadoop fs -mkdir -p /data/hive/log
[root@node1 conf]# hadoop fs -chmod -R 777 /data/hive/warehouse
[root@node1 conf]# hadoop fs -chmod -R 777 /data/hive/tmp
[root@node1 conf]# hadoop fs -chmod -R 777 /data/hive/log
# 用以下命令检查目录是否创建成功
[root@node1 conf]# hadoop fs -ls /user/hive
Found 3 items
drwxrwxrwx - root supergroup 0 2020-12-03 13:36 /data/hive/log
drwxrwxrwx - root supergroup 0 2020-12-03 13:34 /data/hive/tmp
drwxrwxrwx - root supergroup 0 2020-12-03 13:36 /data/hive/warehouse
6、修改hive-site.xml
# 搜索hive.exec.scratchdir,将该name对应的value修改为/data/hive/tmp
<property>
<name>hive.exec.scratchdir</name>
<value>/data/hive/tmp</value>
</property>
# 搜索hive.querylog.location,将该name对应的value修改为/data/hive/log/hadoop
<property>
<name>hive.querylog.location</name>
<value>/data/hive/log/hadoop</value>
<description>Location of Hive run time structured logfile</description>
</property>
# 搜索javax.jdo.option.ConnectionURL,将该name对应的value修改为Mysql的地址
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.168.1.14:3306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connectstring for a JDBC metastore.
To use SSL toencrypt/authenticate the connection, provide
database-specific SSL flag in theconnection URL.
For example,jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
# 搜索javax.jdo.option.ConnectionDriverName,将该name对应的value修改为Mysql驱动类路径
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driverclass name for a JDBC metastore</description>
</property>
# 搜索javax.jdo.option.ConnectionUserName,将对应的value修改为Mysql数据库登录名
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username touse against metastore database</description>
</property>
# 搜索javax.jdo.option.ConnectionPassword,将对应的value修改为Mysql数据库的登录密码
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to useagainst metastore database</description>
</property>
# 创建tmp目录
[root@node1 conf]# mkdir ../tmp
# 把${system:java.io.tmpdir}改成/usr/local/hive/tmp
[root@node1 conf]# sed -i 's#${system:java.io.tmpdir}#/usr/local/hive/tmp#g' hive-site.xml
# 把${system:user.name}改成${user.name}
[root@node1 conf]# sed -i 's#${system:user.name}#${user.name}#g' hive-site.xml
7、修改hive-env.sh
[root@node1 conf]# mv hive-env.sh.template hive-env.sh
[root@node1 conf]# vim hive-env.sh
# 加入以下内容
HADOOP_HOME=/usr/local/hadoop-2.7.2
export HIVE_CONF_DIR=/usr/local/hive/conf
8、下载Mysql驱动包
[root@node1 conf]# cd ../lib/
[root@node1 lib]# wget https://cdn.mysql.com/archives/mysql-connector-java-5.1/mysql-connector-java-5.1.46.zip
[root@node1 lib]# unzip mysql-connector-java-5.1.46.zip
[root@node1 lib]# mv mysql-connector-java-5.1.46/mysql-connector-java-5.1.46.jar .
[root@node1 lib]# rm -rf mysql-connector-java-5.1.46 mysql-connector-java-5.1.46.zip
9、创建hive数据库及授权
[root@node1 ~]# mysql -uroot -p
mysql> create database hive;
mysql> grant all on hive_test@'%' identifide by '123456';
mysql> flush privileges;
10、初始化Mysql
[root@node1 lib]# cd ../bin
[root@node1 bin]# ./schematool -initSchema -dbType mysql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLo
ggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://172.168.1.14:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: hive
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
# 看到schemaTool completed表示初始化成功。
5)启动Hive
[root@node1 lib]# hive
which: no hbase in (/usr/local/jdk1.8.0_181/bin:/usr/local/jdk1.8.0_181/jre/bin:/data/mysql/bin:/usr/local/jdk1.8.0_181/bin:/usr/local/jdk1.8.0_181/jre/bin:/data/mysql/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/bin:/usr/local/hadoop-2.7.2/bin:/root/bin:/bin:/usr/local/hadoop-2.7.2/bin:/usr/local/hive/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/usr/local/hive/lib/hive-common-2.3.7.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> show databases;
OK
default
Time taken: 0.068 seconds, Fetched: 1 row(s)
至此,Hive数据仓库搭建完毕。
若文章图片、下载链接等信息出错,请在评论区留言反馈,博主将第一时间更新!如本文“对您有用”,欢迎随意打赏,谢谢!


评论