
一、Prometheus概述
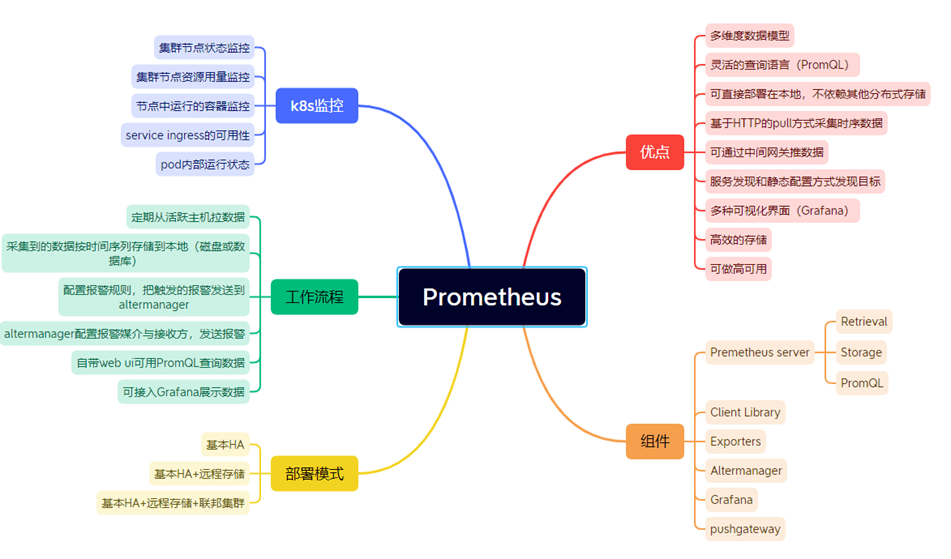
二、基础概念
数据模型:prometheus将所有数据存储为时间序列:属于相同metric名称和相同标签组(键值对)的时间戳值流。
文章源自小柒网-https://www.yangxingzhen.cn/8293.html
metric和标签:每一个时间序列都是由其metric名称和一组标签(键值对)组成唯一标识,标签给prometheus建立了多维度数据模型。
文章源自小柒网-https://www.yangxingzhen.cn/8293.html
实例与任务:在prometheus中,一个可以拉取数据的端点叫做实例(instance),一般等同于一个进程。一组有着同样目标的实例(例如为弹性或可用性而复制的进程副本)叫做任务(job)。文章源自小柒网-https://www.yangxingzhen.cn/8293.html
三、组件架构
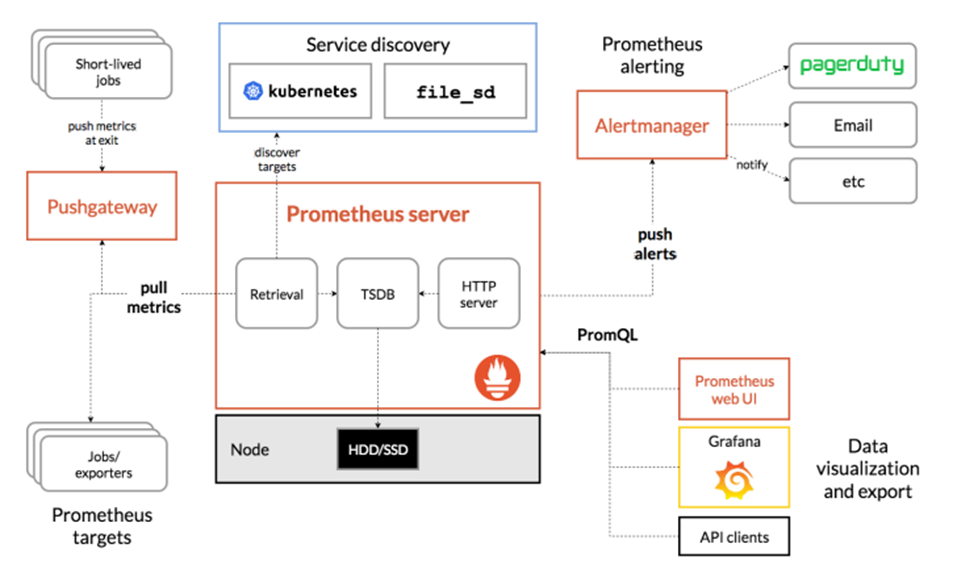 文章源自小柒网-https://www.yangxingzhen.cn/8293.html
文章源自小柒网-https://www.yangxingzhen.cn/8293.html
- prometheus server
Retrieval负责在活跃的target主机上抓取监控指标数据。Storage存储主要是把采集到的数据存储到磁盘中。PromQL是Prometheus提供的查询语言模块。
文章源自小柒网-https://www.yangxingzhen.cn/8293.html
- Exporters
prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到prometheus server端,所有向promtheus server提供监控数据的程序都可以被称为exporter。
文章源自小柒网-https://www.yangxingzhen.cn/8293.html
- Client Library
客户端库,检测应用程序代码,当 Prometheus 抓取实例的HTTP端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到prometheus server端。
文章源自小柒网-https://www.yangxingzhen.cn/8293.html
- Alertmanager
从 Prometheus server端接收到alerts后,会进行去重,分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉, slack 等。
文章源自小柒网-https://www.yangxingzhen.cn/8293.html
- Grafana
监控仪表盘,可视化监控数据。
文章源自小柒网-https://www.yangxingzhen.cn/8293.html
- pushgateway
各个目标主机可上报数据到pushgatewy,然后prometheus server统一从 pushgateway拉取数据。
文章源自小柒网-https://www.yangxingzhen.cn/8293.html
注:基于v1.25.2版kubernetes,其他版本根据情况修改资源版本及配置
1、安装Node-exporter
1)创建namespace命名空间
[root@cmp-k8s-dev-master01 ~]# kubectl create namespace monitor
2)创建配置文件目录
[root@cmp-k8s-dev-master01 ~]# mkdir /opt/monitor
3)通过daemonset部署可使每个节点都有一个Pod来采集数据,node-exporter.yaml
[root@cmp-k8s-dev-master01 ~]# cd /opt/monitor
[root@cmp-k8s-dev-master01 monitor]# vim node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true # 共享宿主机网络和进程
containers:
- name: node-exporter
image: prom/node-exporter:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9100 # 容器暴露端口为9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true # 开启特权模式
args:
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts: # 挂载宿主机目录以收集宿主机信息
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations: # 定义容忍度,使其可调度到默认有污点的master
- operator: "Exists"
volumes: # 定义存储卷
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
4)部署node-exporter
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f node-exporter.yaml
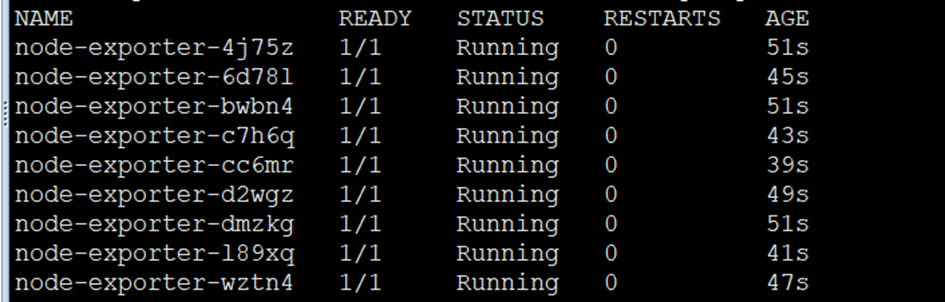
5)查看是否部署成功
[root@cmp-k8s-dev-master01 monitor]# kubectl get pod -n monitor
6)检查node-exporter是否能正常采集到数据
[root@cmp-k8s-dev-master01 monitor]# curl -s http://主机IP:9100/metrics |grep node_load
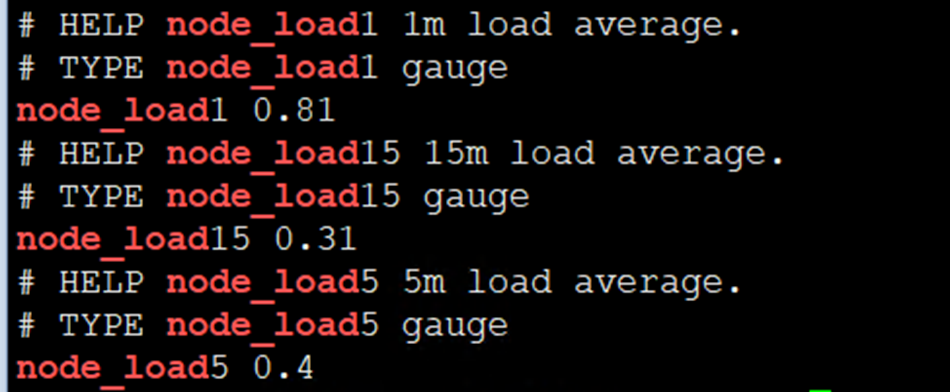
注:出现以上数据代表node-exporter安装成功
2、安装Prometheus Server
1)创建sa账号
[root@cmp-k8s-dev-master01 monitor]# kubectl create serviceaccount monitor -n monitor
2)sa账号授权
[root@cmp-k8s-dev-master01 monitor]# kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor --clusterrole=cluster-admin --serviceaccount=monitor:monitor
3)在指定的node节点创建数据目录,这里我用的是node1
[root@cmp-k8s-dev-node01 ~]# mkdir -p /data/prometheus
[root@cmp-k8s-dev-node01 ~]# chmod 777 /data/prometheus
4)使用configmap配置prometheus
[root@cmp-k8s-dev-master01 monitor]# vim prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-services'
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
5)创建prometheus的configmap
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f prometheus-configmap.yaml
6)通过deployment部署prometheus,(其中nodeName值替换为要安装prometheus server节点的主机名,与刚才创建的/data/promtheus目录在同一节点)
[root@cmp-k8s-dev-master01 monitor]# vim prometheus-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false' # 该容器不会被prometheus发现并监控,其他pod可通过添加该注解(值为true)以服务发现的方式自动被prometheus监控到。
spec:
nodeName: cmp-k8s-dev-node01
serviceAccountName: monitor # 指定sa,使容器有权限获取数据
containers:
- name: prometheus # 容器名称
image: prom/prometheus:v2.27.1 # 镜像名称
imagePullPolicy: IfNotPresent # 镜像拉取策略
command: # 容器启动时执行的命令
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus # 旧数据存储目录
- --storage.tsdb.retention=720h # 旧数据保留时间
- --web.enable-lifecycle # 开启热加载
ports: # 容器暴露的端口
- containerPort: 9090
protocol: TCP # 协议
volumeMounts: # 容器挂载的数据卷
- mountPath: /etc/prometheus # 要挂载到哪里
name: prometheus-config # 挂载谁(与下面定义的volume对应)
- mountPath: /prometheus/
name: prometheus-storage-volume
volumes: # 数据卷定义
- name: prometheus-config # 名称
configMap: # 从configmap获取数据
name: prometheus-config # configmap的名称
- name: prometheus-storage-volume
hostPath:
path: /data/prometheus
type: Directory
7)创建Deployment
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f prometheus-deploy.yaml
8)查看deployment是否部署成功
[root@cmp-k8s-dev-master01 monitor]# kubectl get deployment -n monitor
[root@cmp-k8s-dev-master01 monitor]# kubectl get pod -n monitor
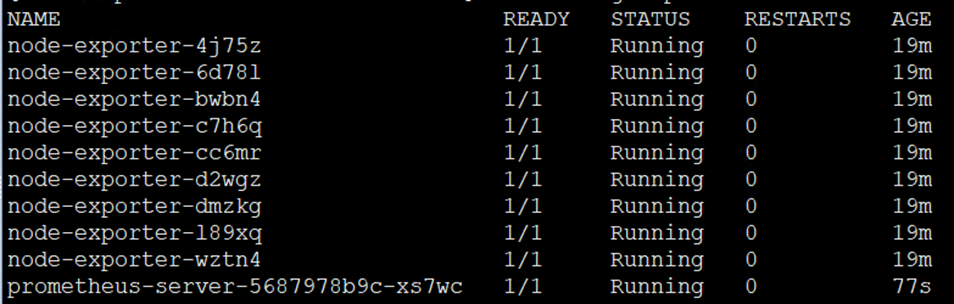
9)创建前端service配置文件,配置内容如下
[root@cmp-k8s-dev-master01 monitor]# vim prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
nodePort: 30090
protocol: TCP
selector:
app: prometheus
component: server
10)创建service
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f prometheus-svc.yaml
11)查看service映射的端口号
[root@cmp-k8s-dev-master01 monitor]# kubectl get svc -n monitor
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 172.10.133.15 <none> 9090:30090/TCP 2m16s
12)浏览器访问prometheus的web界面
# 输入http://node1 IP:30090,如下图

13)查询负载情况验证Prometheus Server是否正常运行
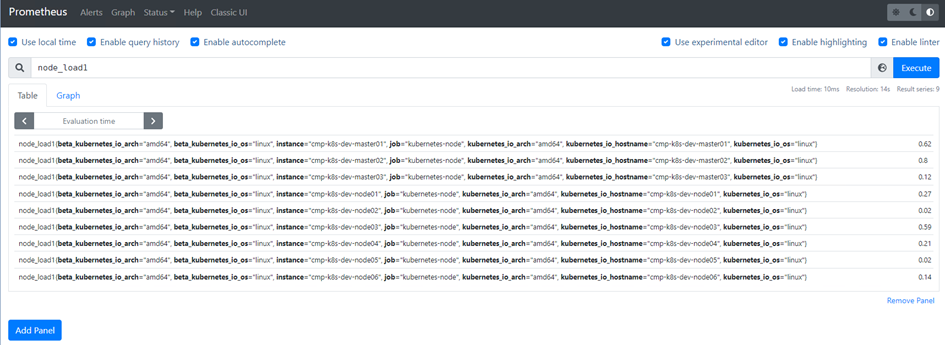
3、安装Grafana
1)创建数据目录并授权
[root@cmp-k8s-dev-node01 ~]# mkdir -p /data/grafana
[root@cmp-k8s-dev-node01 ~]# chmod 777 /data/grafana
2)创建Grafana的deployment配置文件,配置内容如下
[root@cmp-k8s-dev-master01 monitor]# vim grafana-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana-server
namespace: monitor
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
nodeName: cmp-k8s-dev-node01 # 要安装到哪个节点
containers:
- name: grafana
image: grafana/grafana:8.5.14
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
- mountPath: /var/lib/grafana/
name: lib
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
- name: lib
hostPath:
path: /data/grafana/
type: DirectoryOrCreate
注:nodeName的值替换为要安装grafana节点的主机名和创建的目录在同一节点
3)使用deployment部署grafana
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f grafana-deploy.yaml
4)查看Grafana是否创建成功
[root@cmp-k8s-dev-master01 monitor]# kubectl get deployment -n monitor
[root@cmp-k8s-dev-master01 monitor]# kubectl get pod -n monitor
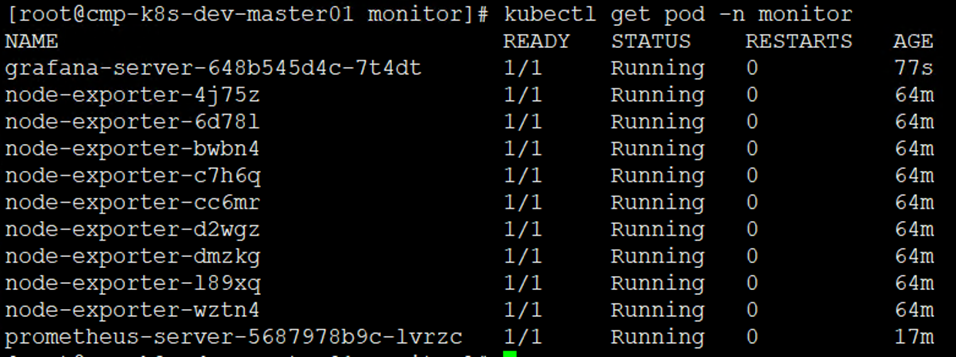
5)创建Grafana前端Service,配置内容如下
[root@cmp-k8s-dev-master01 monitor]# vim grafana-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: grafana
namespace: monitor
spec:
ports:
- port: 80
targetPort: 3000
nodePort: 30000
selector:
k8s-app: grafana
type: NodePort
6)部署Grafana前端service
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f grafana-svc.yaml
7)查看Grafana前端service
[root@cmp-k8s-dev-master01 monitor]# kubectl get svc -n monitor
8)浏览器访问Grafana
# 输入http://node1 IP:30000,如下图
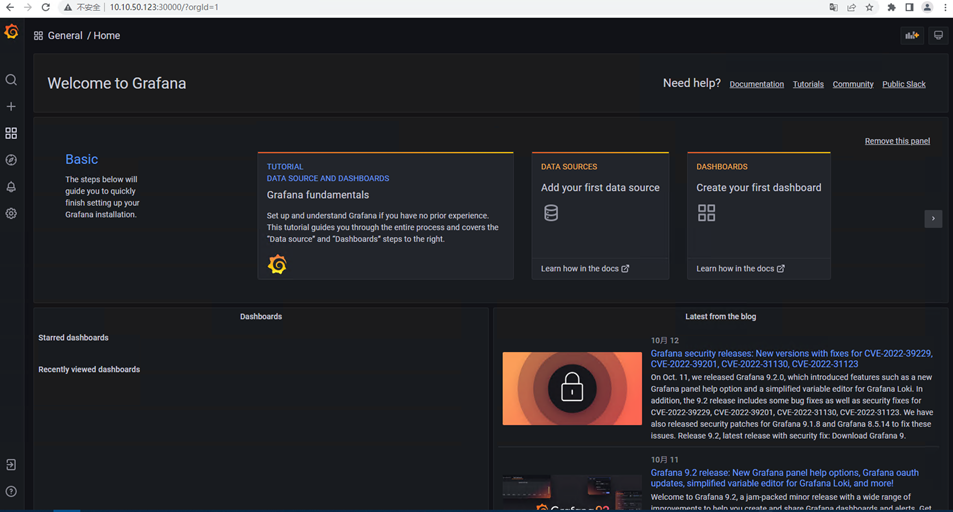
4、配置Grafana
1)添加Prometheus数据源
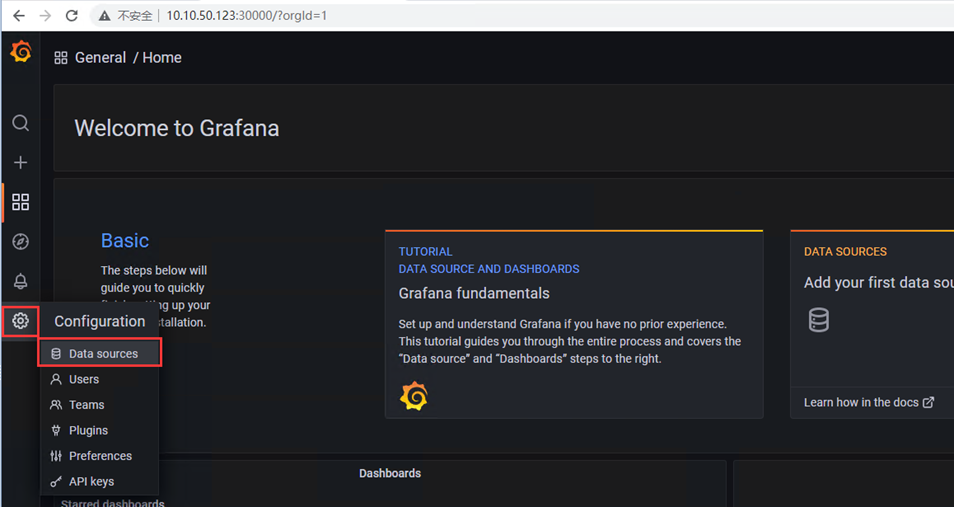
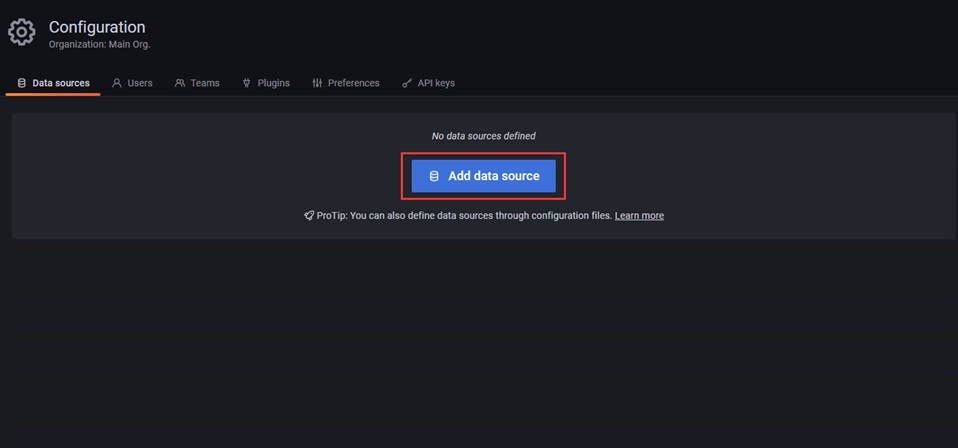
2)选择prometheus,进入配置界面
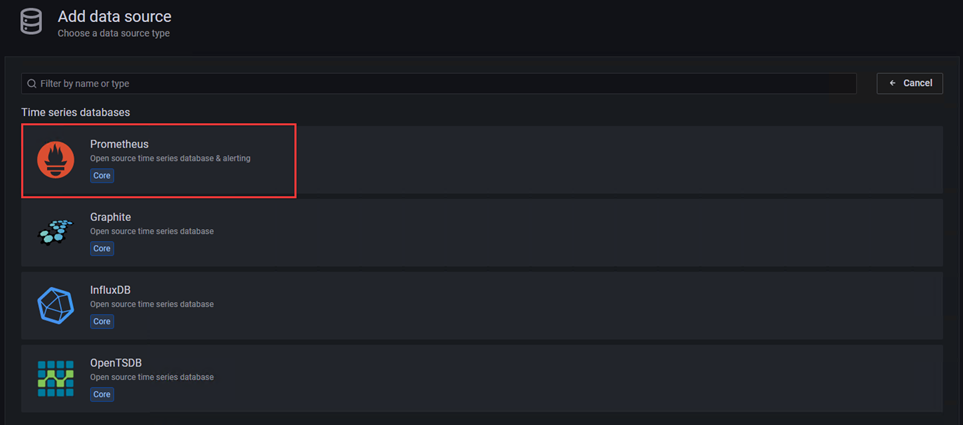
3)配置内容如下
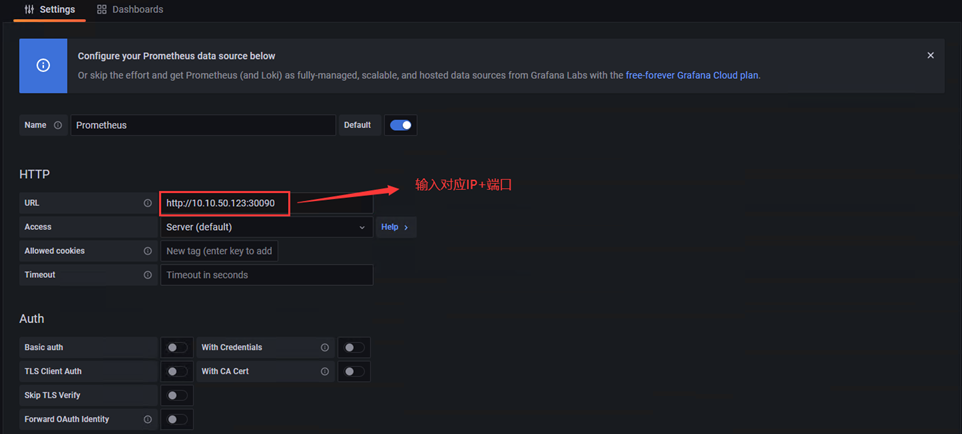
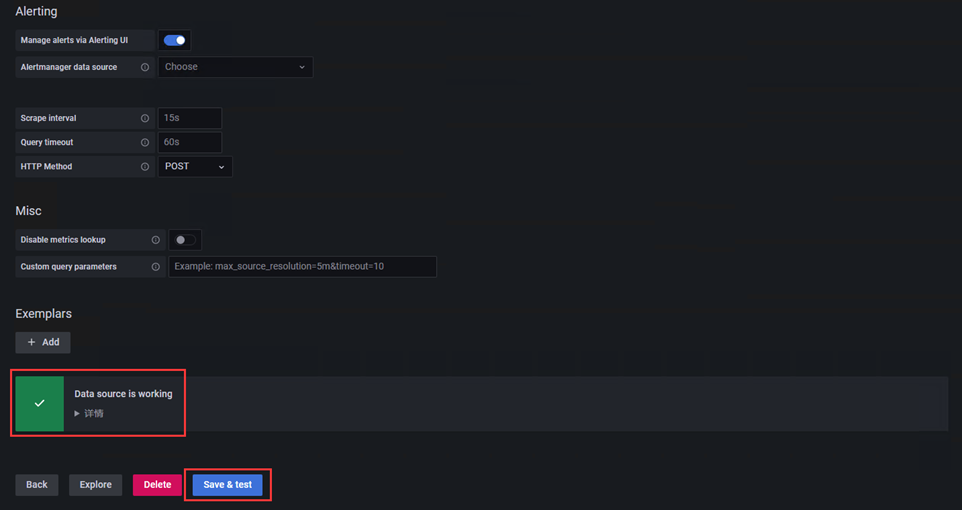
# 配置完成点击左下角Save & Test,出现如Data source is working,说明prometheus数据源配置成功。
4)下载模板
模板地址:https://grafana.com/grafana/dashboards/16098-1-node-exporter-for-prometheus-dashboard-cn-0417-job/
1、点击'+'选项,点击Import
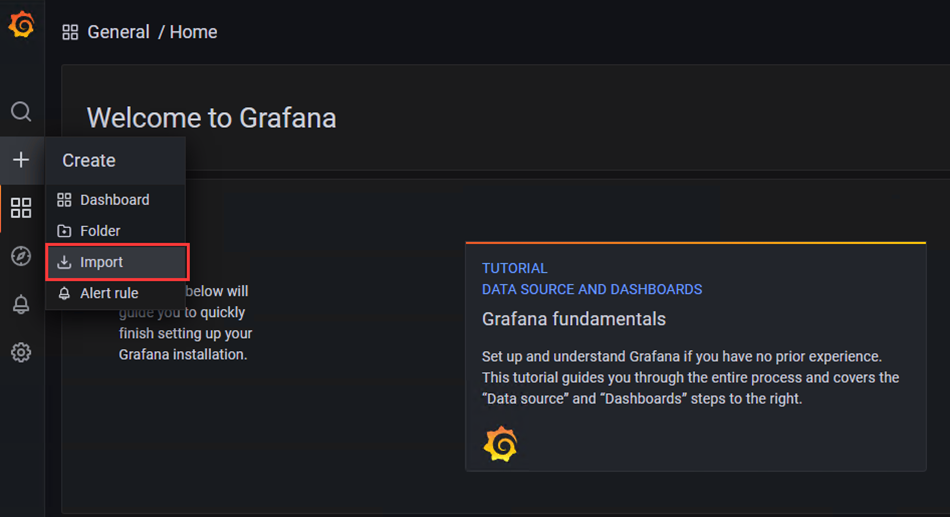
2、选择下载好的json模板文件,点击Import导入

3、查看模板详情
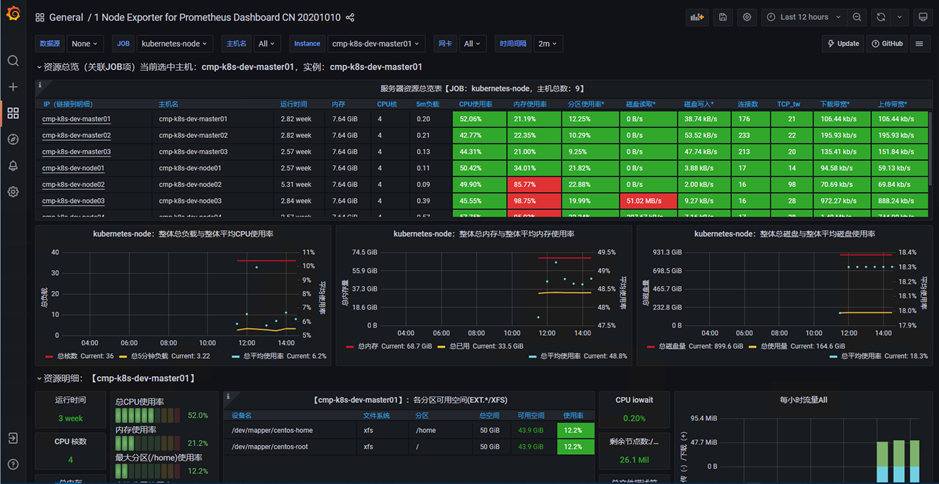
5、安装kube-state-metrics(监控k8s资源状态)
1)创建rbac授权,配置内容如下
[root@cmp-k8s-dev-master01 monitor]# vim kube-state-metrics-rbac.yaml
---
apiVersion: v1 # api版本:v1
kind: ServiceAccount # 资源类型:服务账号
metadata: # 元数据
name: kube-state-metrics # 名称
namespace: monitor # 名称空间
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole # 资源类型:集群角色
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: monitor
2)执行rbac yaml文件
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f kube-state-metrics-rbac.yaml
3)使用deployment安装kube-state-metrics,配置内容如下
[root@cmp-k8s-dev-master01 monitor]# vim kube-state-metrics-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: monitor
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: quay.io/coreos/kube-state-metrics:v1.9.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
4)创建kube-state-metrics
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f kube-state-metrics-deploy.yaml
5)查看是否创建成功
[root@cmp-k8s-dev-master01 monitor]# kubectl get deployment -n monitor
[root@cmp-k8s-dev-master01 monitor]# kubectl get pod -n monitor
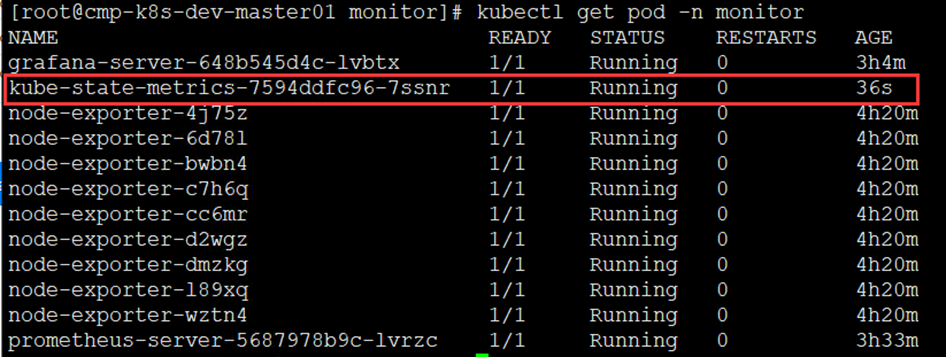
6)创建创建前端service,配置文件如下
[root@cmp-k8s-dev-master01 monitor]# vim kube-state-metrics-svc.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: kube-state-metrics
namespace: monitor
labels:
app: kube-state-metrics
spec:
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics
7)应用yaml文件
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f kube-state-metrics-svc.yaml
8)查看svc
[root@cmp-k8s-dev-master01 monitor]# kubectl get svc -n monitor
9)导入模板
模板地址:https://grafana.com/grafana/dashboards/15661-1-k8s-for-prometheus-dashboard-20211010/
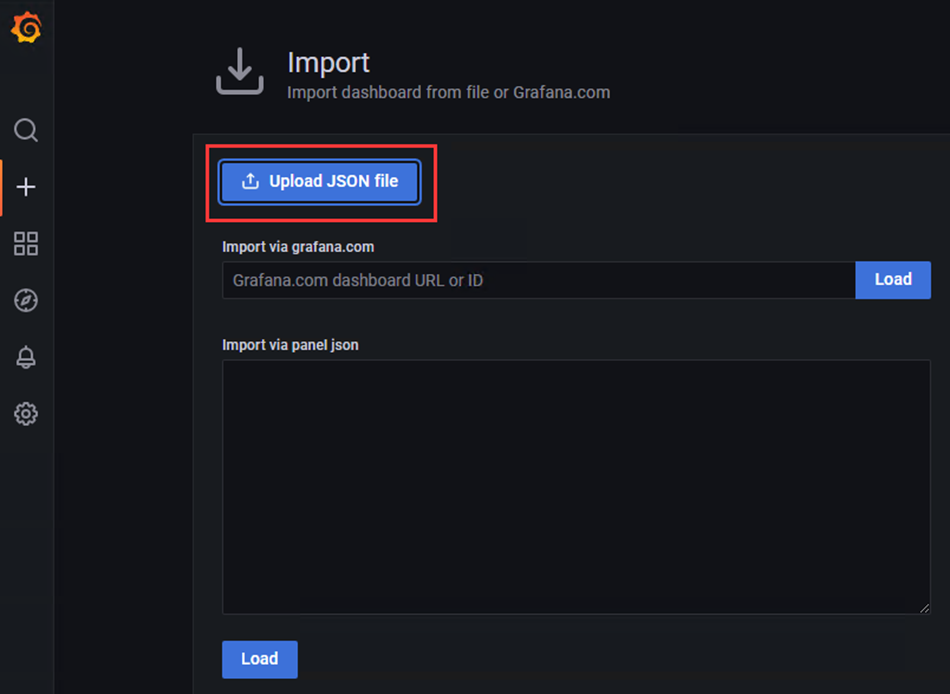
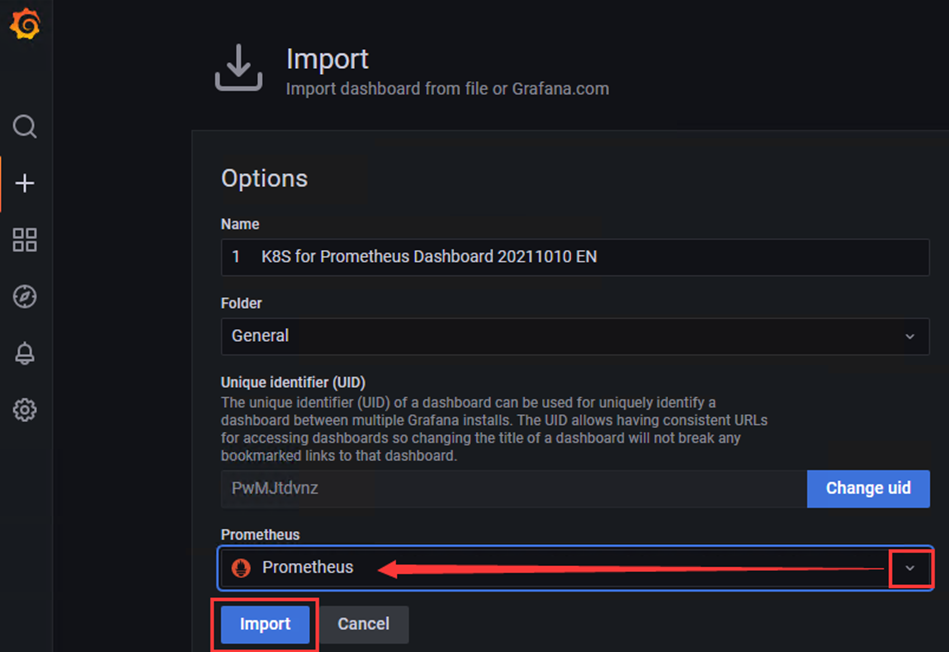
# 导入json模板文件
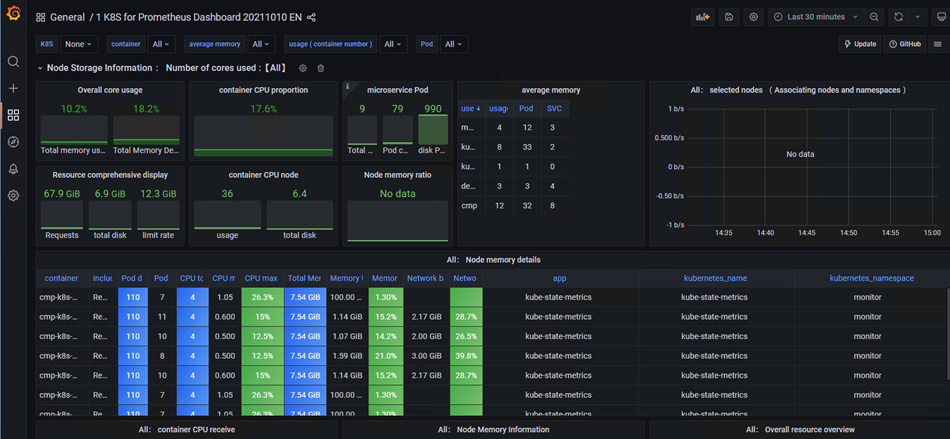
# 查看监控状态
6、安装Altermanager
1)创建altermanager配置和告警模板
[root@cmp-k8s-dev-master01 monitor]# vim alertmanager-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitor
data:
alertmanager.yml: | # altermanager配置文件
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465' # 发送者的SMTP服务器
smtp_from: '675583110@qq.com' # 发送者的邮箱
smtp_auth_username: '675583110@qq.com' # 发送者的邮箱用户名
smtp_auth_password: 'Aa123456' # 发送者授权密码
smtp_require_tls: false
templates:
- '/etc/alertmanager/email.tmpl'
route: # 配置告警分发策略
group_by: ['alertname'] # 采用哪个标签作为分组依据
group_wait: 10s # 组告警等待时间(10s内的同组告警一起发送)
group_interval: 10s # 两组告警的间隔时间
repeat_interval: 10m # 重复告警的间隔时间
receiver: email # 接收者配置
receivers:
- name: 'email' # 接收者名称(与上面对应)
email_configs: # 接收邮箱配置
- to: 'yangxingzhen@tisson.cn' # 接收邮箱(填要接收告警的邮箱)
headers: { Subject: "Prometheus [Warning] 报警邮件" }
html: '{{ template "email.html" . }}'
send_resolved: true # 是否通知已解决的告警
email.tmpl: | # 告警模版
{{ define "email.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{ range .Alerts }}
告警程序:Prometheus_Alertmanager <br>
告警级别:{{ .Labels.severity }} <br>
告警状态:{{ .Status }} <br>
告警类型:{{ .Labels.alertname }} <br>
告警主机:{{ .Labels.instance }} <br>
告警详情:{{ .Annotations.description }} <br>
触发时间:{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{ range .Alerts }}
告警程序:Prometheus_Alertmanager <br>
告警级别:{{ .Labels.severity }} <br>
告警状态:{{ .Status }} <br>
告警类型:{{ .Labels.alertname }} <br>
告警主机:{{ .Labels.instance }} <br>
告警详情:{{ .Annotations.description }} <br>
触发时间:{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
恢复时间:{{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- end }}
2)创建altermanager的configmap
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f alertmanager-configmap.yaml
3)创建Prometheus告警规则
[root@cmp-k8s-dev-master01 monitor]# vim prometheus-alertmanager-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
rule_files:
- /etc/prometheus/rules.yml
alerting:
alertmanagers:
- static_configs:
- targets: ["10.10.50.123:30093"]
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-services'
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'kubernetes-ingresses'
kubernetes_sd_configs:
- role: ingress
relabel_configs:
- source_labels: [__meta_kubernetes_ingress_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__meta_kubernetes_ingress_scheme,__address__,__meta_kubernetes_ingress_path]
regex: (.+);(.+);(.+)
replacement: ${1}://${2}${3}
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_ingress_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_ingress_name]
target_label: kubernetes_name
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
- job_name: 'kubernetes-schedule'
scrape_interval: 5s
static_configs:
- targets: ['10.10.50.114:10259']
- job_name: 'kubernetes-controller-manager'
scrape_interval: 5s
static_configs:
- targets: ['10.10.50.114:10257']
- job_name: 'kubernetes-kube-proxy'
scrape_interval: 5s
static_configs:
- targets: ['10.10.50.114:10249']
- job_name: 'kubernetes-etcd'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt
cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt
key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key
scrape_interval: 5s
static_configs:
- targets: ['10.10.50.114:2379','10.10.50.115:2379','10.10.50.116:2379']
rules.yml: |
groups:
- name: example
rules:
- alert: kube-proxy的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: kube-proxy的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: scheduler的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: scheduler的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: controller-manager的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: controller-manager的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: apiserver的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: apiserver的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: etcd的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: etcd的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: kube-state-metrics的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"
value: "{{ $value }}%"
threshold: "80%"
- alert: kube-state-metrics的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"
value: "{{ $value }}%"
threshold: "90%"
- alert: coredns的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"
value: "{{ $value }}%"
threshold: "80%"
- alert: coredns的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"
value: "{{ $value }}%"
threshold: "90%"
- alert: kube-proxy打开句柄数>600
expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kube-proxy打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-schedule打开句柄数>600
expr: process_open_fds{job=~"kubernetes-schedule"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-schedule打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-schedule"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-controller-manager打开句柄数>600
expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-controller-manager打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-apiserver打开句柄数>600
expr: process_open_fds{job=~"kubernetes-apiserver"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-apiserver打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-etcd打开句柄数>600
expr: process_open_fds{job=~"kubernetes-etcd"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-etcd打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-etcd"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: coredns
expr: process_open_fds{k8s_app=~"kube-dns"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"
value: "{{ $value }}"
- alert: coredns
expr: process_open_fds{k8s_app=~"kube-dns"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"
value: "{{ $value }}"
- alert: kube-proxy
expr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: scheduler
expr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-controller-manager
expr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-apiserver
expr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-etcd
expr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kube-dns
expr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: HttpRequestsAvg
expr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"
value: "{{ $value }}"
threshold: "1000"
- alert: Pod_restarts
expr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor"} > 0
for: 2s
labels:
severity: warnning
annotations:
description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"
value: "{{ $value }}"
threshold: "0"
- alert: Pod_waiting
expr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"
value: "{{ $value }}"
threshold: "1"
- alert: Pod_terminated
expr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"
value: "{{ $value }}"
threshold: "1"
- alert: Etcd_leader
expr: etcd_server_has_leader{job="kubernetes-etcd"} == 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_leader_changes
expr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_failed
expr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_db_total_size
expr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"
value: "{{ $value }}"
threshold: "10G"
- alert: Endpoint_ready
expr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"
value: "{{ $value }}"
threshold: "1"
- name: Node_exporter Down
rules:
- alert: Node实例已宕机
expr: up == 0
for: 15s
labels:
severity: Emergency
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "Node_exporter客户端已停止运行超过15s"
- name: Memory Usage High
rules:
- alert: 物理节点-内存使用率过高
expr: 100 - (node_memory_Buffers_bytes + node_memory_Cached_bytes + node_memory_MemFree_bytes) / node_memory_MemTotal_bytes * 100 > 90
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "内存使用率 > 90%,当前内存使用率:{{ $value }}"
- name: Cpu Load 1
rules:
- alert: 物理节点-CPU(1分钟负载)
expr: node_load1 > 9
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "CPU负载(1分钟) > 9,前CPU负载(1分钟):{{ $value }}"
- name: Cpu Load 5
rules:
- alert: 物理节点-CPU(5分钟负载)
expr: node_load5 > 10
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "CPU负载(5分钟) > 10,当前CPU负载(5分钟):{{ $value }}"
- name: Cpu Load 15
rules:
- alert: 物理节点-CPU(15分钟负载)
expr: node_load15 > 11
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "CPU负载(15分钟) > 11,当前CPU负载(15分钟):{{ $value }}"
- name: Cpu Idle High
rules:
- alert: 物理节点-CPU使用率过高
expr: 100 - (avg by(job,instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "CPU使用率 > 90%,当前CPU使用率:{{ $value }}"
- name: Root Disk Space
rules:
- alert: 物理节点-根分区使用率
expr: (node_filesystem_size_bytes {mountpoint ="/"} - node_filesystem_free_bytes {mountpoint ="/"}) / node_filesystem_size_bytes {mountpoint ="/"} * 100 > 90
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "根分区使用率 > 90%,当前根分区使用率:{{ $value }}"
- name: opt Disk Space
rules:
- alert: 物理节点-opt分区使用率
expr: (node_filesystem_size_bytes {mountpoint ="/opt"} - node_filesystem_free_bytes {mountpoint ="/opt"}) / node_filesystem_size_bytes {mountpoint ="/opt"} * 100 > 90
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "/opt分区使用率 > 90%,当前/opt分区使用率:{{ $value }}"
- name: SWAP Usage Space
rules:
- alert: 物理节点-Swap分区使用率
expr: (1 - (node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes)) * 100 > 90
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "Swap分区使用率 > 90%,当前Swap分区使用率:{{ $value }}"
- name: Unusual Disk Read Rate
rules:
- alert: 物理节点-磁盘I/O读速率
expr: sum by (job,instance) (irate(node_disk_read_bytes_total[2m])) / 1024 / 1024 > 200
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "磁盘I/O读速率 > 200 MB/s,当前磁盘I/O读速率:{{ $value }}"
- name: Unusual Disk Write Rate
rules:
- alert: 物理节点-磁盘I/O写速率
expr: sum by (job,instance) (irate(node_disk_written_bytes_total[2m])) / 1024 / 1024 > 200
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "磁盘I/O写速率 > 200 MB/s,当前磁盘I/O读速率:{{ $value }}"
- name: UnusualNetworkThroughputOut
rules:
- alert: 物理节点-网络流出带宽
expr: sum by (job,instance) (irate(node_network_transmit_bytes_total[2m])) / 1024 / 1024 > 200
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "网络流出带宽 > 200 MB/s,当前网络流出带宽{{ $value }}"
- name: TCP_Established_High
rules:
- alert: 物理节点-TCP连接数
expr: node_netstat_Tcp_CurrEstab > 5000
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "TCP连接数 > 5000,当前TCP连接数:[{{ $value }}]"
- name: TCP_TIME_WAIT
rules:
- alert: 物理节点-等待关闭的TCP连接数
expr: node_sockstat_TCP_tw > 5000
for: 3m
labels:
severity: Warning
annotations:
summary: "{{ $labels.job }}"
address: "{{ $labels.instance }}"
description: "等待关闭的TCP连接数 > 5000,当前等待关闭的TCP连接数:[{{ $value }}]"
4)应用yaml文件
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f prometheus-alertmanager-configmap.yaml
5)创建挂载目录
[root@cmp-k8s-dev-master01 monitor]# mkdir -p /data/alertmanager
[root@cmp-k8s-dev-master01 monitor]# chmod 777 /data/alertmanager
5)创建Altermanager的yaml文件,配置内容如下
[root@cmp-k8s-dev-master01 monitor]# vim alertmanager-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: monitor
labels:
app: alertmanager
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
component: server
template:
metadata:
labels:
app: alertmanager
component: server
spec:
nodeName: cmp-k8s-dev-node01
serviceAccountName: monitor # 指定sa,使容器有权限获取数据
containers:
- name: alertmanager # 容器名称
image: bitnami/alertmanager:0.24.0 # 镜像名称
imagePullPolicy: IfNotPresent # 镜像拉取策略
args: # 容器启动时执行的命令
- "--config.file=/etc/alertmanager/alertmanager.yml"
- "--log.level=debug"
ports: # 容器暴露的端口
- containerPort: 9093
protocol: TCP # 协议
name: alertmanager
volumeMounts: # 容器挂载的数据卷
- mountPath: /etc/alertmanager # 要挂载到哪里
name: alertmanager-config # 挂载谁(与下面定义的volume对应)
- mountPath: /alertmanager/
name: alertmanager-storage-volume
- name: localtime
mountPath: /etc/localtime
volumes: # 数据卷定义
- name: alertmanager-config # 名称
configMap: # 从configmap获取数据
name: alertmanager # configmap的名称
- name: alertmanager-storage-volume
hostPath:
path: /data/alertmanager
type: Directory
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
6)部署Alertmanager
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f alertmanager-deploy.yaml
7)创建前端service,配置内容如下
[root@cmp-k8s-dev-master01 monitor]# vim alertmanager-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
name: alertmanager
kubernetes.io/cluster-service: 'true'
name: alertmanager
namespace: monitor
spec:
ports:
- name: alertmanager
nodePort: 30093
port: 9093
protocol: TCP
targetPort: 9093
selector:
app: alertmanager
sessionAffinity: None
type: NodePort
8)应用yaml文件
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f alertmanager-svc.yaml
9)生成etcd-certs用于prometheus
[root@cmp-k8s-dev-master01 monitor]# kubectl -n monitor create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
10)删除之前安装的prometheus
[root@cmp-k8s-dev-master01 monitor]# kubectl delete -f prometheus-deploy.yaml
11)修改prometheus-deploy.yaml
[root@cmp-k8s-dev-master01 monitor]# vim prometheus-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false' # 该容器不会被prometheus发现并监控,其他pod可通过添加该注解(值为true)以服务发现的方式自动被prometheus监控到。
spec:
nodeName: cmp-k8s-dev-node01
serviceAccountName: monitor # 指定sa,使容器有权限获取数据
containers:
- name: prometheus # 容器名称
image: prom/prometheus:v2.27.1 # 镜像名称
imagePullPolicy: IfNotPresent # 镜像拉取策略
command: # 容器启动时执行的命令
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus # 旧数据存储目录
- --storage.tsdb.retention=720h # 旧数据保留时间
- --web.enable-lifecycle # 开启热加载
ports: # 容器暴露的端口
- containerPort: 9090
protocol: TCP # 协议
volumeMounts: # 容器挂载的数据卷
- mountPath: /etc/prometheus # 要挂载到哪里
name: prometheus-config # 挂载谁(与下面定义的volume对应)
- mountPath: /prometheus/
name: prometheus-storage-volume
- mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/
name: k8s-certs
volumes: # 数据卷定义
- name: prometheus-config # 名称
configMap: # 从configmap获取数据
name: prometheus-config # configmap的名称
- name: prometheus-storage-volume
hostPath:
path: /data/prometheus
type: Directory
- name: k8s-certs
secret:
secretName: etcd-certs
12)创建Pod
[root@cmp-k8s-dev-master01 monitor]# kubectl apply -f prometheus-deploy.yaml
13)查看prometheus是否部署成功
[root@cmp-k8s-dev-master01 monitor]# kubectl get pods -n monitor
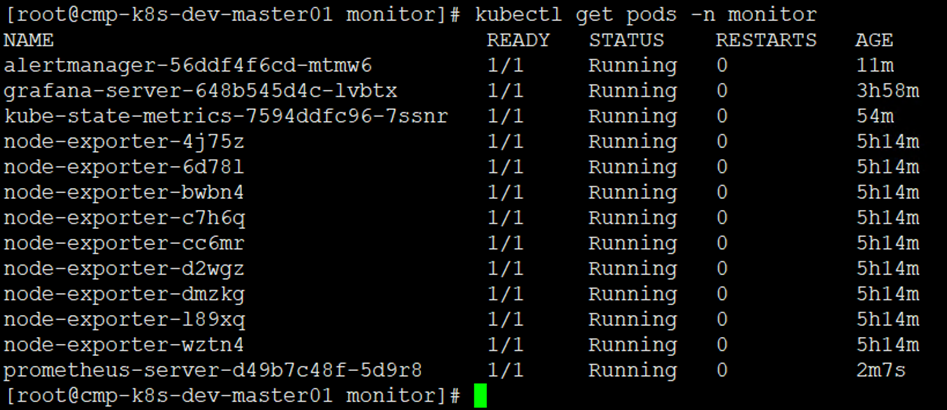
14)浏览器访问alertmanager
# 输入http://IP:30093,如下图
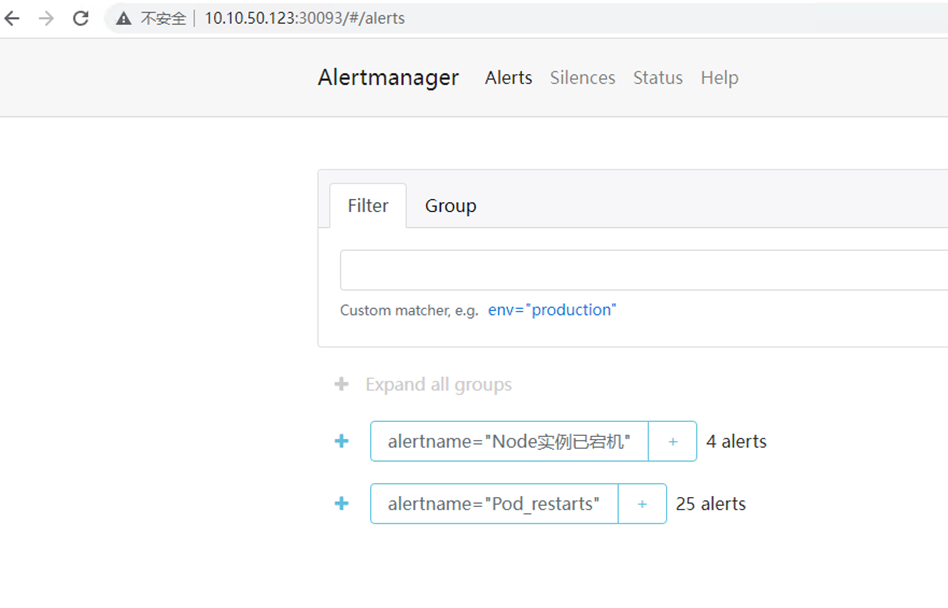
15)查看邮件告警
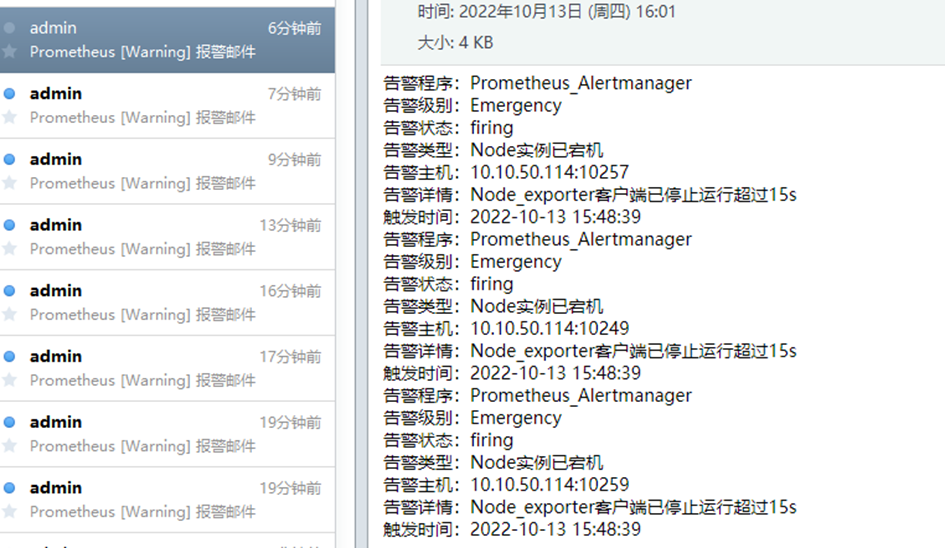
16)故障处理
注意:以下操作在生产环境慎重执行,可能会导致集群故障
kubeadm部署k8s集群,kube-controller-manager和kube-scheduler的监听IP默认为127.0.0.1,如果需要将其改为0.0.0.0用以提供外部访问,可分别修改对应的manifest文件。可按如下方法处理:
# kube-scheduler
[root@cmp-k8s-dev-master01 monitor]# sed -i 's/127.0.0.1/0.0.0.0/g' /etc/kubernetes/manifests/kube-scheduler.yaml
修改如下内容:
--bind-address==127.0.0.1修改成--bind-address=0.0.0.0
httpGet:
hosts: 127.0.0.1改成0.0.0.0
# kube-controller-manager
[root@cmp-k8s-dev-master01 monitor]# sed -i 's/127.0.0.1/0.0.0.0/g' /etc/kubernetes/manifests/kube-controller-manager.yaml
修改如下内容:
--bind-address==127.0.0.1修改成--bind-address=0.0.0.0
httpGet:
hosts: 127.0.0.1改成0.0.0.0
# 重启各节点的kubelet
[root@cmp-k8s-dev-master01 monitor]# systemctl restart kubelet
# kube-proxy
[root@cmp-k8s-dev-master01 monitor]# kubectl edit configmap kube-proxy -n kube-system
修改如下内容:
metricsBindAddress: ""修改成metricsBindAddress: "0.0.0.0"
# 删除Pod
[root@cmp-k8s-dev-master01 monitor]# kubectl get pod -n monitor
[root@cmp-k8s-dev-master01 monitor]# kubectl delete pod -n kube-system kube-proxy-qjpxx
若文章图片、下载链接等信息出错,请在评论区留言反馈,博主将第一时间更新!如本文“对您有用”,欢迎随意打赏,谢谢!


评论